





今やビジネスに不可欠となった生成AIですが、多くの方が生成AIのブラックボックス問題に直面し、本格的な導入に二の足を踏んでいるのではないでしょうか。
AIの判断プロセスが不透明なことは、特に金融、医療、法務といった高リスク領域において、コンプライアンスや説明責任の観点から致命的な障壁となっています。
しかし、この根深い問題を根本から解決するかもしれない、非常にエキサイティングな研究がOpenAIから発表されました。それが「スパース回路(Sparse Circuits)」に関する研究です。
この記事では、以下の点を徹底的に解き明かしていきます。
- そもそも、なぜAIは「ブラックボックス」と呼ばれるのか?
- OpenAIの「スパース回路」研究は、一体何が革新的なのか?
- この研究が、AIを導入する企業のビジネスに、将来どのような影響を与えるのか?
- 「透明なAI」が実現するまで、私たちは今何をすべきか?
この記事を最後まで読めば、AIの“中身”を理解しようとする最先端の取り組みと、企業が今すぐ取るべき実務的なアクションが明確になるでしょう。
今なら、100ページ以上にのぼる企業のための生成AI活用ガイドを配布中!基礎から活用、具体的な企業の失敗事例から成功事例まで、1冊で全網羅しています!

目次
なぜAIは“ブラックボックス”なのか?「説明可能なAI」が求められる背景
まず、私たちが日常的に使っているChatGPTのような高性能AIが、なぜ「ブラックボックス」と呼ばれるのか、その理由を簡単におさらいしましょう。

LLMは高度だが「なぜその回答なのか」を説明できない
大規模言語モデル(LLM)は、非常に高度な文章生成や要約、対話が可能です。私たちは「入力(プロンプト)」を入れれば「出力(回答)」が得られることは知っています。
しかし、その「入力」が「出力」になるまでの途中の処理プロセスが、人間には全く理解できないのです
これは、LLMが「ディープラーニング(深層学習)」という技術を基にしているためです。ディープラーニングは、人間の脳の神経細胞(ニューロン)を模した「ニューラルネットワーク」を何層にも(時には何百、何千層も)重ねた複雑な構造を持っています。
AIが学習する過程で、このネットワーク内にある何十億、何兆という接続(パラメータ)が自動的に調整されます。その結果、あまりに複雑な「計算の迷路」が出来上がり、開発者自身でさえ、「なぜAIがその結論に至ったのか」を正確に説明することができなくなってしまうのです。
| AIの可視性 | 説明 |
|---|---|
| 入力 (Input) | ユーザーが入力するプロンプトやデータ。(例:「日本の首都は?」) |
| 処理 (Process) | (ブラックボックス) 膨大なニューラルネットワーク内で何が起こっているか不明。 |
| 出力 (Output) | AIが生成する回答や結果。(例:「日本の首都は東京です。」) |
既存の「説明可能なAI(XAI)」の限界
もちろん、このブラックボックス問題を解決しようとする試みは以前からありました。「XAI(Explainable AI:説明可能なAI)」と呼ばれる研究分野です。
XAIには、例えば「LIME(ライム)」と呼ばれる技術があります。これは、AIの回答に対して「入力データのどの部分が、その回答に強く影響したか」を後から分析する手法です。
- 例:AIが画像を「猫」と判断した場合
LIMEは、画像の「耳」「ヒゲ」「目」といった部分が「猫」という判断に強く寄与したことを可視化します。
こうした技術は、AIの判断の「手がかり」をある程度示してくれますが、根本的な限界も抱えています。
LLM向けの解釈は“部分的可視化”止まりで、構造理解には至っていない
既存のXAI技術は、AIの内部構造を完全に解明するものではありません。あくまで「入力と出力の関係性」から、AIの振る舞いを間接的に“推測”しているに過ぎないのです。
特にChatGPTのようなLLMは、従来の画像認識AIとは比べ物にならないほど巨大で複雑です。
既存XAIの限界
- 部分的な説明: 「なぜこの単語を選んだか」は分かっても、「なぜこの文章構成になったか」という全体的なロジックは説明できません。
- 構造の不可解さ: AIの“脳”であるニューラルネットワークが、全体としてどのように連携して「思考」しているのか、その根本的なアルゴリズム(仕組み)は謎のままでした。
- 信頼性の問題: 説明自体が不正確である可能性も否定できず、その説明を100%信頼することもできません。
従来のAIは、いわば「答えは出せるが、計算過程は書けない」生徒のようなものでした。この状態では、ビジネスの重要な意思決定を任せるのは非常に危険です。
OpenAIの「スパース回路」研究とは何か
この絶望的とも思えるブラックボックス問題に、正面からメスを入れたのが、OpenAIの「スパース回路(Sparse Circuits)」研究です。
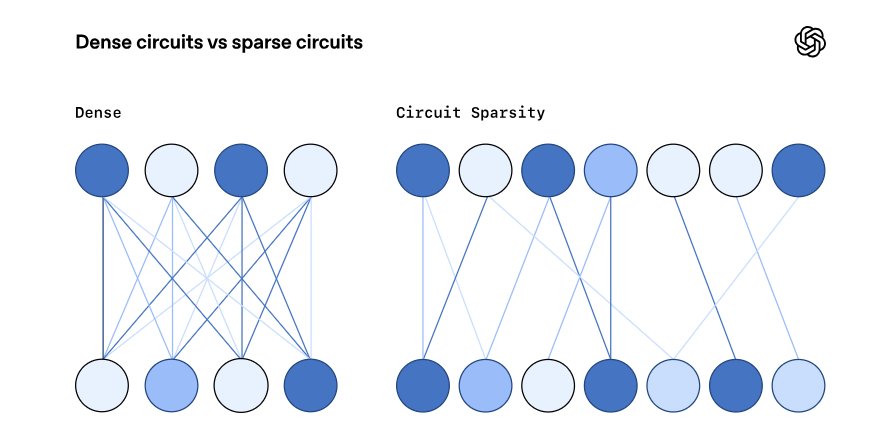
密なモデル vs スパース(疎)なモデル
この研究を理解する鍵は、「密(Dense)」と「疎(Sparse)」の違いにあります。
従来の密なモデル (Dense Models)
- ニューラルネットワーク内のニューロン(神経細胞)が、互いに密に、複雑に接続されています。
- 1つのニューロンが「文法を処理する機能」と「特定の単語(例:『猫』)を記憶する機能」など、複数の役割を同時に担っている(ポリセマンティック)と考えられています。
- 結果として、どのニューロンがどの機能を持っているのか解読不能になります。
スパースなモデル (Sparse Models)
- OpenAIは、あえてニューロン間の接続を大幅に制限(ほとんどの接続をゼロにする)したモデルを訓練しました。
- これにより、各ニューロンが「この機能だけを担当する」という専門家(モノセマンティック)**になるように誘導します。
- 接続が「疎(まばら)」になることで、情報の流れが単純化され、人間が追いやすくなるのではないか、というのがこの研究の核心です。
| モデルタイプ | 接続の様子 | ニューロンの役割 | 解釈可能性 |
|---|---|---|---|
| 密なモデル | 複雑に絡み合ったスパゲッティ状態 | 1つが多機能(ポリセマンティック) | 非常に低い |
| スパースなモデル | 整理された配線図に近い状態 | 1つが単一機能(モノセマンティック) | 高い(と期待される) |
OpenAIが目指している「メカニスティック解釈可能性」
OpenAIがこの研究で目指しているのは、「メカニスティック解釈可能性(Mechanistic Interpretability)」と呼ばれる、非常に野心的なゴールです。
これは、前述のXAIのように「AIの振る舞いを外から推測する」レベルではなく、AIの内部計算を「完全にリバースエンジニアリングする」ことを意味します。
メカニスティック解釈可能性とは?
AIの動作を、ニューロンや接続(重み)といった最も基本的な部品レベルまで分解し、その振る舞い(アルゴリズム)を完全に説明しようとするアプローチ。
つまり、AIの“脳”を解剖し、「どの神経(ニューロン)が、どのように信号(情報)を伝え合って、最終的な思考(出力)に至っているのか」を、配線図レベルで理解しようという試みです。
簡単なタスクから“回路構造の意味”を読み出すアプローチ
いきなりGPT-4のような超巨大モデルを解明するのは不可能です。そこでOpenAIは、まず比較的小さなスパースモデルに、非常に簡単なタスクを与えました。
そして、そのタスクを実行するために「最低限必要なニューロンの接続経路」だけを特定しました。この最小限の経路を、彼らは「回路(Circuit)」と呼んでいます。
彼らの狙いは、この「回路」が、人間が理解できるような「意味のあるアルゴリズム」を持っているかどうかを調べることでした。
Pythonクォート補完などで見えた“人間が読めるアルゴリズム”
そして、非常に興味深い結果が得られました。
例えば、「Pythonのコードで、文字列の最後のクォート(引用符)を正しく補完する」というタスクです。
(例: text = ‘hello と入力されたら、最後に ‘ を補完する)
このタスクを与えられたスパースモデル内部を解析したところ、人間がプログラムを書く時と非常によく似た、驚くほど論理的な「回路」が形成されていたのです。
スパースモデルが学習した「回路」の動き
- 記憶: 最初のトークンが
‘(シングルクォート)か“(ダブルクォート)かを検出し、その情報を特定のニューロンにエンコード(記憶)する。 - 伝達: 文字列の途中にある他のトークン(例:
hello)は無視し、記憶したクォートの情報を最後のトークンまで伝達する。 - 実行: 最後のトークンで、記憶していた情報(
‘または“)に基づいて、一致するクォートを出力する。
これはもはや「AIがなんとなく学習した」というレベルではなく、人間が読んで理解できるアルゴリズムそのものです。この回路は、タスク実行に必要不可欠であり、この回路の一部を削除するとモデルはタスクに失敗しました。
研究が明らかにしたこと:能力と“理解しやすさ”は両立できる可能性
この研究結果は、AIの未来にとって非常に重要な示唆に富んでいます。
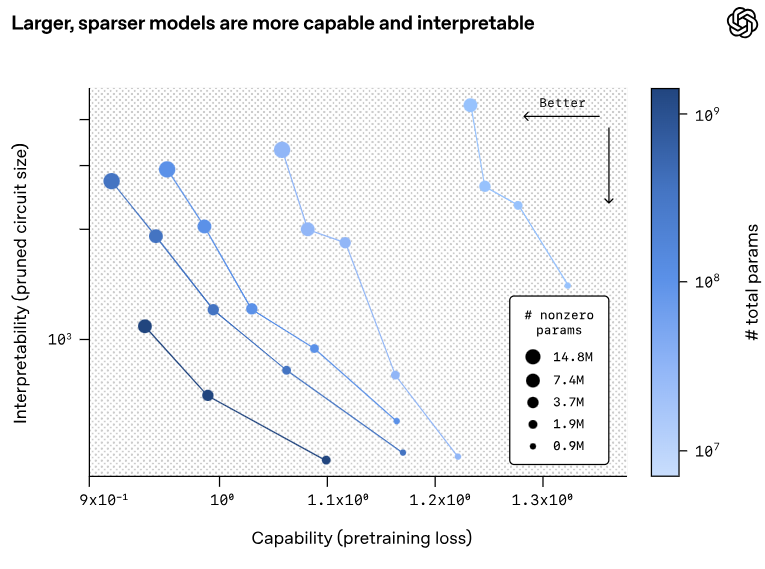
モデルが大きく、かつスパースになるほど回路が整う
最も驚くべき発見は、「モデルの能力」と「解釈可能性(分かりやすさ)」の関係性です。
OpenAIがモデルのサイズ(パラメータ数)を大きくし、同時にスパース性(接続のまばらさ)を高めるように訓練したところ、モデルの能力(タスクの正解率)を維持、あるいは向上させながら、内部の「回路」はより単純で解釈しやすくなったのです。
以下の図(グラフ)は、その関係性を示しています。
グラフの意味
- グラフの左上に行くほど「能力が高く、かつ解釈しやすい」理想的なモデルであることを意味します。
- モデルサイズをスケールアップ(大きく)させると、全体が左上にシフトしています。
- これは、「モデルを大きくすれば、能力と解釈可能性の両方を改善できる」可能性を示唆しています。
「能力は高いが中身は複雑」の固定観念が覆りつつある
これは、AI業界の長年の「常識」を覆す結果かもしれません。
これまでは、「AIの能力を上げれば(モデルを大きくすれば)、中身はより複雑なブラックボックスになる」というトレードオフ(二律背反)が当たり前だと考えられてきました。
しかし、今回の研究は、「適切な訓練法(スパース化)を用いれば、高性能でありながら、中身はクリーンで理解しやすいAIを作れるかもしれない」という希望の光を示しました。
ただし現段階では、モデル規模・カバレッジともにまだ限定的
もちろん、興奮しすぎるのはまだ早いです。OpenAI自身も、この研究がまだ「非常に野心的な賭け」の第一歩にすぎないことを認めています。
研究の限界点(課題)
- モデル規模: 今回実験に使われたスパースモデルは、GPT-5のような最先端のフロンティアモデルと比べれば、まだはるかに小さいです。
- タスクの単純さ: 解明できた「回路」は、Pythonのクォート補完のような、比較的単純なアルゴリズムに限られています。
- カバレッジ: モデル全体の振る舞いのうち、解釈できたのはまだごく一部にすぎません。
このアプローチが、人間の言語が持つ複雑さ、曖昧さ、そして創造性といった高度な振る舞いを解明するまでにスケールアップできるかは、まだ誰にも分かりません。
この研究がビジネス(AIガバナンス)にもたらす影響
とはいえ、私はこの「スパース回路」研究の方向性が、将来のビジネスシーン、特に「AIガバナンス」のあり方を根本から変える可能性があると見ています。
高リスク領域(医療・金融・公共)での説明責任と相性が良い
AIのブラックボックス性が最も問題となるのは、判断ミスが許されない「高リスク領域」です。
- 医療: AIがレントゲン写真から「がんの疑いあり」と診断した。その根拠は?
- 金融: AIが住宅ローン申請を「否決」した。その理由は?
- 司法: AIが「再犯リスク高」と判断した。何を基準に?
現状のブラックボックスAIでは、この「なぜ?」に答えることができません。しかし、もし将来、スパースモデルのように内部の「回路」が解読可能になれば、「このAIは、申請者の“この”情報と“あの”情報を参照する回路を使い、規定“XXX”に基づき否決しました」と、アルゴリズムレベルで説明責任を果たせるようになるかもしれません。
将来のAI監査やガバナンスで「回路レベルの根拠」が要求される可能性
EU(欧州連合)の「AI法」や、ニューヨーク市の「自動雇用ツール法」など、世界的にAIの透明性を求める規制が強まっています。
今はまだ「バイアスの有無を監査する」といったレベルですが、解釈可能性の研究が進めば、規制当局や監査法人が、AIベンダーに対して「そのAIの判断プロセスを、回路レベルで提出しなさい」と要求する未来が来るかもしれません。
| 現在のAI監査 | 将来(予想)のAI監査 |
|---|---|
| 対象: 入力データと出力結果の統計的偏り(バイアス)。 | 対象: AI内部の「回路」そのもの。 |
| 内容: 「男女間で採用率に不公平な差がないか?」 | 内容: 「採用判断に、性別や人種に関連する回路が(意図せず)使われていないか?」 |
| レベル: 結果論的なチェック。 | レベル: プロセス(アルゴリズム)の根本的なチェック。 |
透明性が高いモデル=“採用しやすいモデル” になる未来シナリオ
企業がAIを導入する際、複数のベダーを比較検討します。その時、「性能」や「コスト」が同等であれば、何が決め手になるでしょうか?
間違いなく透明性と信頼性です。
- A社(ブラックボックスAI): 「性能は最高ですが、なぜその回答かは分かりません」
- B社(透明なAI): 「性能は同等で、我々のAIは判断根拠を回路レベルで提示できます」
経営者として、株主や顧客に対して説明責任を負う立場なら、どちらのAIを採用すべきかは明白です。「透明性が高いAI」は、それ自体が企業の法的・倫理的リスクを低減する強力な付加価値となります。
今すぐ企業ができるAIガバナンス実践術
「スパース回路」が実用化されるのはまだ先の話です。では、AIが依然としてブラックボックスである“今”、私たち日本企業は何をすべきでしょうか?
未来の「透明なAI」時代に備えつつ、現在の「不透明なAI」と賢く付き合うための、実務的なアクションを3つ提案します。
AI運用ポリシーに「確認ルール(透明性基準)」を追加する
AIがブラックボックスであることを前提とした、社内ルール(AIガバナンス)の整備が急務です。
AIガバナンスで定めるべきルールの例
- 人間の介在: AIの出力を業務に利用する際は、必ず人間の専門家がレビューし、最終的な意思決定を行う。
- 判断基準: AIの回答が「根拠不明」または「説明不可能」な場合、その出力を重要な意思決定(採用、評価、与信など)に利用することを禁止する。
- 責任の所在: AIの利用によって問題が発生した場合の責任分界点と、インシデント対応フローを明確にする。
- 記録の保持: AIの判断プロセスを(可能な限り)記録・保存し、事後検証(監査)に備える。
ベンダー比較では“公開姿勢”だけをチェックする
現時点でAIベンダーに「メカニスティック解釈可能性」を求めても意味はありません。しかし、ベンダーの「透明性に対する企業姿勢」は今すぐチェックできます。
AIベンダー選定チェックポイント
- 安全性ガイドライン: AIの安全性や倫理に関するガイドラインを策定し、公開しているか?
- データプライバシー: 入力したデータをAIの再学習に使用するか? 使用しない(オプトアウト)選択肢が明確に提供されているか?
- 人手レビューの有無: 企業の機密情報が、ベンダーの従業員によってレビューされる(見られる)可能性はないか?
- 説明可能性への取り組み: ブラックボックス問題やXAIについて、ベンダーがどのような研究開発や情報発信を行っているか?

ChatGPTの情報漏洩リスクを3分で診断|NotebookLMでプライバシーポリシーを読み解く方法
社内研修で“AIの弱点“を全員で共有する
最も重要なのは、経営層から現場の従業員まで、全員がAIの限界とリスクを正しく理解することです。
「AIは完璧ではなく、時には嘘をつき(ハルシネーション)、間違った根拠に基づき、バイアス(偏見)を助長する可能性がある」という事実を、社内研修で徹底的に共有してください。
全従業員が守るべきAI利用の基本ルール
- 機密情報を入力しない: 顧客情報、個人情報、社外秘の情報をAIに入力しない。
- 出力を鵜呑みにしない: AIの回答は「参考意見」の一つと捉え、必ずファクトチェックを行う。
- 最終判断は人間が: AIに「決めさせる」のではなく、AIを「道具」として使い、判断は人間が行う。
- バイアスを疑う: AIの回答が、特定の属性(性別、年齢、人種など)に対して不公平でないか、常に意識する。
デジライズでは、生成AIの導入研修を行っています。個別のミーティングで業務内容をヒアリングし、現場で本当に使えるAI活用法を一緒に考えるところからスタートします。実際に使えるように、AIの専門家が伴走いたしますので、AI担当者がいない企業様でもご安心ください。
まずは情報収集からでも歓迎です。
導入の流れや支援内容をまとめた資料をこちらからご覧いただけます。

まとめ:「スパース回路」と透明なAIの未来
今回は、AIの「ブラックボックス問題」という長年の課題に、OpenAIが「スパース回路」というアプローチで挑んだ画期的な研究について解説しました。
AIの内部構造をリバースエンジニアリングし、その動作アルゴリズムを人間が理解できるようにする「メカニスティック解釈可能性」は、まだ始まったばかりの挑戦です。
しかし、この研究は「高性能なAI」と「理解可能(透明)なAI」は両立しうるという、未来に向けた力強い証拠(Proof of Concept)を示しました。
私たちが今使っているAIは、まだ不透明で、リスクをはらんでいます。
だからこそ、企業は今、AIガバナンスを徹底し、AIの弱点を理解し、賢く使いこなす「守り」の姿勢が求められます。
しかし、スパース回路のような研究が進む先に、AIの判断根拠を私たちが完全に理解し、その“思考”の安全性を検証できる「攻め」の未来が待っているかもしれません。
この技術革新の最前線を追い続けることが、AI時代を生き抜くビジネスリーダーにとって、今最も重要なことだと私は確信しています。
参考
OpenAI『Understanding neural networks through sparse circuits』
OpenAI『Weight-sparse transformers have interpretable circuits』
OpenAI『Scaling and evaluating sparse autoencoders』
この記事の著者 / 編集者

