





2026年5月6日、AnthropicがClaude Managed Agentsに3つの新機能を一気に投入しました。
- dreaming — エージェントが過去のセッションから自分で学ぶ
- outcomes — 「何ができたら完成か」を定義して、採点→自動やり直しを回す
- multiagent — リーダーが専門エージェントにタスクを並列で振り分ける
法律AIのHarveyではタスク完了率が約6倍に、文書レビューのWisedocsではレビュー時間が50%短縮と、Anthropicの公式発表で具体的な数字が出ています。
この記事では、3機能それぞれの仕組みと使いどころを整理したうえで、APIでの使い方と料金まで解説していきます。
今なら、生成AIの基礎知識から社内導入の6ステップ・定着のポイントまでを1冊にまとめた「はじめての生成AI社内導入ガイド」を無料で配布中!何から始めればいいか分からない方でも、これ1冊で導入の流れがつかめます。

目次
そもそもClaude Managed Agentsとは?
Claude Managed Agentsは、Anthropicが提供するホスト型のAIエージェント実行基盤です。2026年4月8日にパブリックベータとして公開されました。
通常、AIエージェントを動かそうとすると、自前でエージェントループを回すコード、ツール実行環境、サンドボックスなどを構築する必要があります。Managed Agentsは、これらをAnthropicのクラウドコンテナ上でまるごと提供してくれるサービスです。
わかりやすく言えば、「Claudeに仕事を丸投げして、終わったら結果だけ受け取れるインフラ」です。
4つの基本概念
Managed Agentsは次の4つの概念で構成されています。
| 概念 | 役割 |
|---|---|
| Agent | モデル・システムプロンプト・ツール・MCPサーバーの組み合わせを定義したもの |
| Environment | Python・Node.jsなどがインストールされたクラウドコンテナのテンプレート |
| Session | あるタスクを実行するAgentのランタイムインスタンス(実行単位) |
| Events | アプリとエージェント間でやり取りするメッセージ(SSE形式でストリーミング) |
Claude Codeで自動化を組んでいる方は、「Claude Codeが裏で回しているエージェントループを、API経由でクラウド上に出したもの」とイメージすると近いです。
Claude Codeの基本についてはこちらの記事で詳しく解説しています。

Claude Codeとは?Web版やCoworkとの使い分けから使い方・料金を徹底解説
dreaming(ドリーミング)— エージェントが「寝ている間に学ぶ」
dreamingは、エージェントが過去のセッション履歴を横断して自分のメモリを再構成する機能です。現在リサーチプレビューとして提供されており、利用にはAnthropicへのアクセスリクエストが必要です。
何をする機能なのか
dreamingが動くと、エージェントは以下の処理を自動で実行します。
- 既存のメモリストアと過去のセッション履歴を読み込む
- 重複・陳腐化したメモリエントリを削除する
- セッション横断で見えるパターンを抽出し、整理されたメモリを再構築する
人間に例えるなら「一日の終わりに、今日やったことを振り返って、自分のノートを整理する」行為です。個別のセッションでは見過ごしがちな繰り返しパターン——たとえば「このファイル形式は毎回エラーが出るから、先にこの手順を踏んでおくべき」といった知見を、エージェントが自分で発見して記憶に書き込みます。
Harveyの事例:完了率が約6倍に
法律AI企業のHarveyは、dreamingの導入テストでタスク完了率が約6倍に向上したとAnthropicが公式ブログで報告しています。
Harveyのエージェントは、法務文書のドラフト作成・ファイル形式の変換・ツール操作といった複雑なワークフローを処理しています。dreamingによって、過去セッションで学んだファイル形式の回避策やツールの使い方パターンがメモリに残り、次回以降のセッションで同じ失敗を繰り返さなくなったことが改善の主因です。
対応モデルと利用方法
| 項目 | 内容 |
|---|---|
| 対応モデル | Claude Opus 4.7 / Claude Sonnet 4.6(公式Docsで最新の対応状況を確認してください) |
| ステータス | リサーチプレビュー |
| 利用開始方法 | Anthropicの申請フォームからアクセスリクエスト |
outcomes(アウトカムズ)— 採点基準を定義して自動で品質を上げる
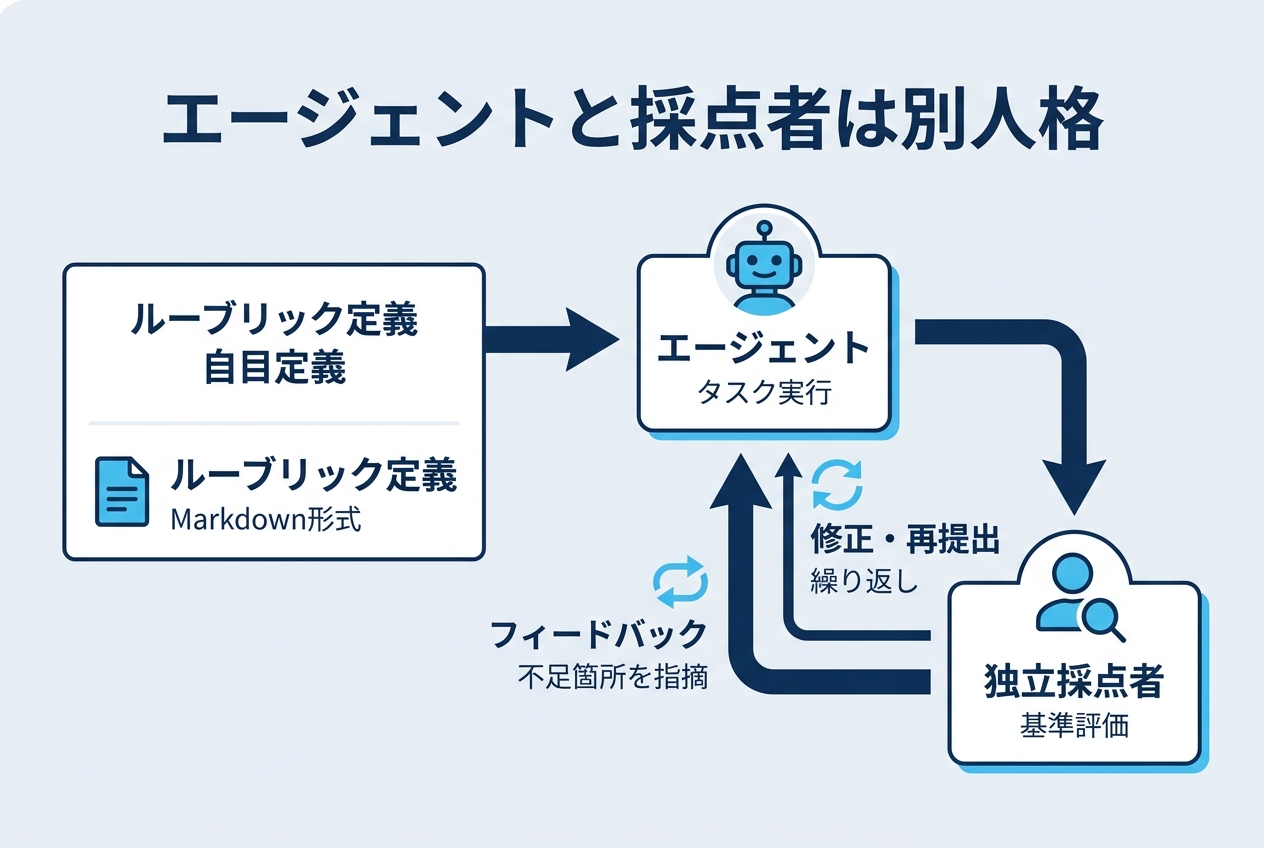
outcomesは、「何ができていれば完成か」をルーブリック(採点基準)として定義し、独立した採点者(Grader)がエージェントの成果物を評価→フィードバック→再実行のサイクルを自動で回す機能です。現在リサーチプレビューとして提供されており、利用にはアクセスリクエストが必要です。
仕組み:エージェントと採点者は別人格
outcomesの最大の特徴は、採点者がエージェント本体とは別のコンテキストウィンドウで動作する点です。
エージェントが「自分の出力を自分で採点する」場合、どうしても自分の思考プロセスに引きずられてバイアスが入ります。outcomesではこれを設計レベルで排除しています。
処理の流れは以下の通りです。
- あなたがMarkdown形式のルーブリック(採点基準)を定義する
user.define_outcomeイベントでセッションに送信する- エージェントがタスクを実行する
- 独立した採点者がルーブリックの各基準に照らして評価する
- 基準を満たしていなければ、不足箇所をフィードバックとしてエージェントに返す
- エージェントが修正して再提出する
- すべての基準を満たすか、最大イテレーション数に達するまで繰り返す
公式ベンチマーク
Anthropicの公式発表によると、outcomesを使った場合の改善幅は以下の通りです。
| 指標 | 改善幅 |
|---|---|
| タスク成功率(全体) | 最大+10ポイント |
| docx生成の成功率 | +8.4ポイント |
| pptx生成の成功率 | +10.1ポイント |
特に難易度の高いタスクほど改善幅が大きいとされています。
Wisedocsの事例:レビュー時間50%短縮
文書レビューサービスのWisedocsでは、outcomesを導入した結果、レビュー処理が50%高速化したとAnthropicが報告しています。チームの品質基準をルーブリックとして定義することで、採点者がその基準に沿ってエージェントの出力を検証し、品質を維持しながらスピードが上がった形です。
APIでの使い方(Python例)
session = client.beta.sessions.create(
agent=agent.id,
environment_id=environment.id,
title="Financial analysis on Costco",
)
client.beta.sessions.events.send(
session_id=session.id,
events=[
{
"type": "user.define_outcome",
"description": "Build a DCF model for Costco in .xlsx",
"rubric": {"type": "text", "content": RUBRIC},
"max_iterations": 5,
}
],
)主要なパラメータは以下の通りです。
| パラメータ | 内容 |
|---|---|
description | タスクの説明(何を作るか) |
rubric | 採点基準。インラインテキストまたはFiles APIでアップロードしたファイルID |
max_iterations | 最大やり直し回数。デフォルト3、最大20 |
採点結果のステータスは5種類あります。
| ステータス | 意味 |
|---|---|
satisfied | すべての基準を満たした |
needs_revision | 不足あり→エージェントが次のイテレーションを開始 |
max_iterations_reached | 最大回数に到達。最後の修正を試みてからセッション終了 |
failed | ルーブリックとタスクが根本的に矛盾している場合 |
interrupted | ユーザーが中断した場合 |

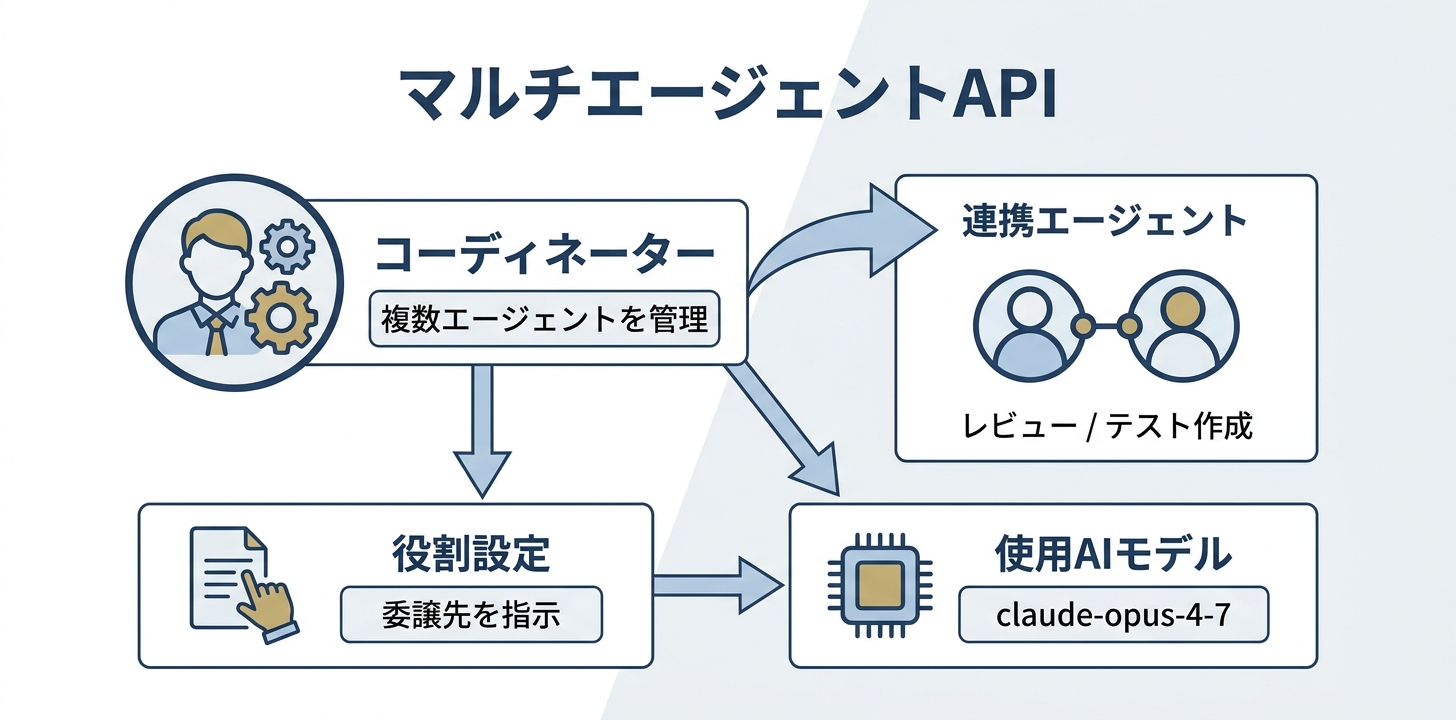
multiagent(マルチエージェント)— チームで仕事を分担する
multiagentは、コーディネーター(リーダー)エージェントが複雑なタスクを分解し、専門エージェントに委譲して並列実行する仕組みです。現在リサーチプレビューとして提供されており、利用にはアクセスリクエストが必要です。
仕組み:共有ファイルシステム+独立コンテキスト
multiagentの設計は、実際のチームの仕事の進め方に近いものです。
- すべてのエージェントは同じコンテナとファイルシステムを共有する
- ただし各エージェントは独自のセッションスレッド(コンテキスト分離済)で動作する
- スレッドは永続的で、コーディネーターは過去のやり取りを記憶したまま同じ専門エージェントに追加依頼できる
チームのSlackを想像するとわかりやすいかもしれません。全員が同じGoogleドライブ(ファイルシステム)にアクセスしつつ、それぞれの仕事は個別のスレッドで進めて、リーダーが全体を取りまとめる——そんな構造です。
3つの推奨パターン
Anthropicの公式ドキュメントでは、multiagentの有効な使い方として3つのパターンが示されています。
| パターン | 内容 | 具体例 |
|---|---|---|
| 並列化 | 独立した作業を同時に展開→コーディネーターが統合 | 複数ソースの検索・複数ファイルの分析 |
| 専門分化 | ドメイン専門のエージェントにルーティング | セキュリティ担当・ドキュメント担当・テスト担当 |
| エスカレーション | 難しいサブタスクだけ上位モデルに委譲 | 日常タスクはHaiku、難問だけOpusに回す |
Spiralの事例:Haiku+Opusの組み合わせ
Every社のライティングエージェント「Spiral」は、multiagentとoutcomesを組み合わせた構成を採用しています。リードエージェントをHaikuで回し、品質が必要なサブタスクだけOpusに委譲することで、コストと品質のバランスを取っています。
APIでの定義例(Python)
coordinator = client.beta.agents.create(
name="Engineering Lead",
model="claude-opus-4-7",
system="コードレビューはreviewer、テスト作成はtest_writerに委譲する。",
tools=[
{"type": "agent_toolset_20260401"},
],
multiagent={
"type": "coordinator",
"agents": [
{"type": "agent", "id": reviewer_agent.id},
{"type": "agent", "id": test_writer_agent.id},
],
},
)制約事項
| 制約 | 内容 |
|---|---|
| 委譲の深さ | 1階層のみ(コーディネーター→専門エージェント。それ以上の入れ子は不可) |
| 登録エージェント数 | multiagent.agentsに最大20体 |
| 同時並列スレッド | 最大25 |
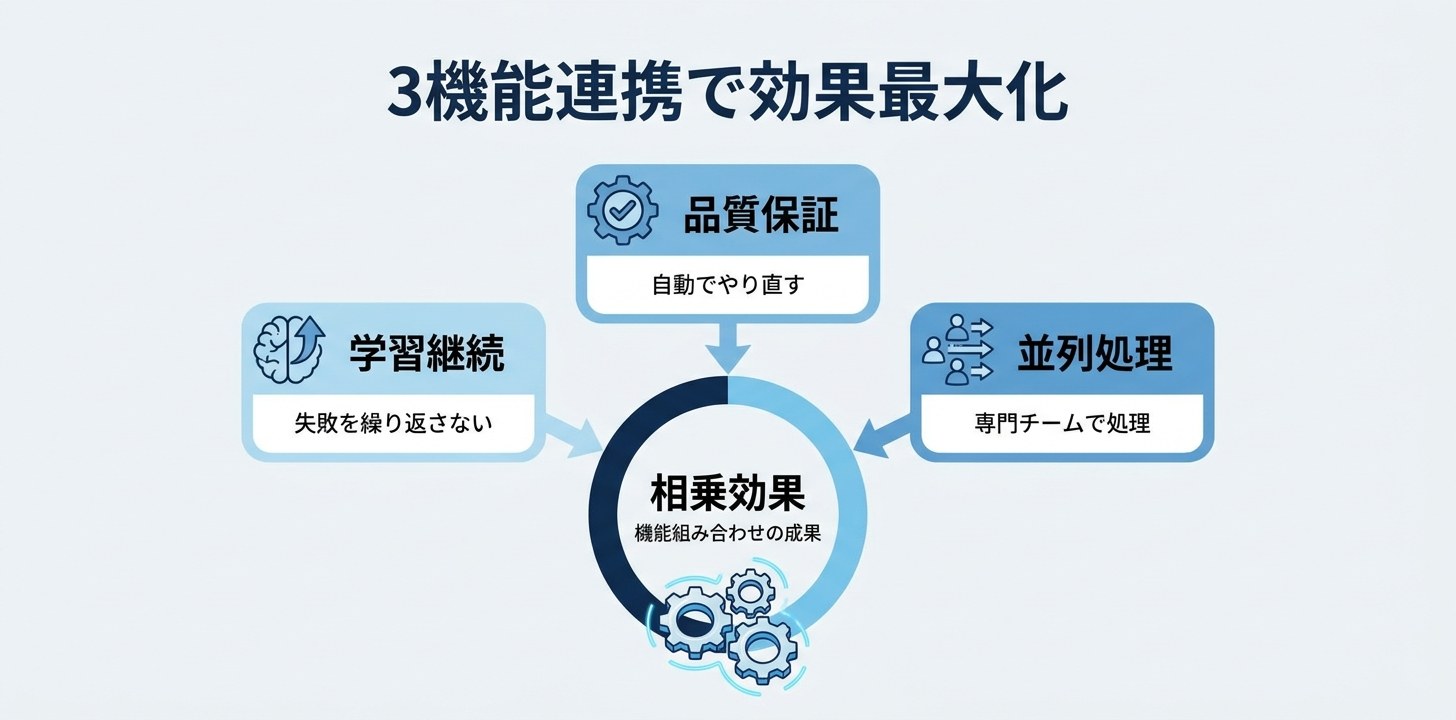
3機能の関係を整理する
dreaming・outcomes・multiagentは独立した機能ですが、組み合わせることで効果が掛け算になります。
| 機能 | 何を解決するか | 一言で |
|---|---|---|
| dreaming | セッション間の学習断絶 | 「昨日の失敗を今日は繰り返さない」 |
| outcomes | 成果物の品質ばらつき | 「採点基準に達するまで自動でやり直す」 |
| multiagent | 単一エージェントの処理限界 | 「専門チームで並列処理する」 |
たとえば、multiagentで複数の専門エージェントを並列で走らせつつ、outcomesでコーディネーターの最終出力を品質保証し、dreamingで各エージェントがセッションをまたいで学習する——という構成が組めます。
Claude Managed Agentsの料金体系
Managed Agentsの料金は、モデルのトークン料金 + セッションランタイム料金の2層構造です。
トークン料金(モデル別)
| モデル | 入力 | 出力 |
|---|---|---|
| Claude Opus 4.7 | $5 / 100万トークン | $25 / 100万トークン |
| Claude Sonnet 4.6 | $3 / 100万トークン | $15 / 100万トークン |
| Claude Haiku 4.5 | $1 / 100万トークン | $5 / 100万トークン |
セッションランタイム料金
- $0.08 / セッション時間(ミリ秒単位で課金)
- ユーザー入力待ち・ツール確認待ちなどのアイドル状態はカウントされない
具体的なコスト感
Anthropicの公式ドキュメントに掲載されている計算例です。
Claude Opus 4.7で1時間のコーディングセッション(入力50,000トークン・出力15,000トークン)の場合:
| 項目 | 金額 |
|---|---|
| 入力トークン | $0.25 |
| 出力トークン | $0.375 |
| ランタイム | $0.08 |
| 合計 | $0.705 |
プロンプトキャッシュを活用した場合(入力の40,000トークンがキャッシュヒット):合計$0.525。
1時間のエージェント実行が1ドル未満に収まるのは、自前でサーバーを立てる場合のインフラコストと比較してかなり安価です。
APIの始め方
Managed Agentsを使い始めるには、以下が必要です。
- Claude APIキー(Managed Agents基盤自体はすべてのAPIアカウントでデフォルト有効)
- ベータヘッダー: すべてのリクエストに
anthropic-beta: managed-agents-2026-04-01を付与(SDKは自動設定) - dreaming・outcomes・multiagentはアクセスリクエストが必要: 3機能はいずれもリサーチプレビュー段階のため、Anthropicの申請フォームから利用申請してください。
レート制限
| 操作 | 制限 |
|---|---|
| 作成系(agents, sessions, environments等) | 60リクエスト/分 |
| 読取系(retrieve, list, stream等) | 600リクエスト/分 |
実務でどう使えるか — 3つのシナリオ
ここまでの解説を踏まえて、あなたの現場で使えそうな活用シナリオを3つ挙げます。
シナリオ1:ドキュメント生成の品質保証
outcomesを使って、提案書・レポート・マニュアルなどの生成品質を自動で担保する構成です。
- ルーブリックに「必須項目チェックリスト」「フォーマット規約」「数値の一貫性」を定義
- エージェントが初稿を作成 → 採点者が基準に照らしてチェック → 不足があれば自動修正
- 最大イテレーション5回程度で品質を安定させつつ、人間のレビュー負担を削減
シナリオ2:コードレビューの並列化
multiagentで、セキュリティ・パフォーマンス・テストカバレッジなど観点別のレビュアーを並列で走らせる構成です。
- コーディネーターがPRの差分を各専門エージェントに配布
- セキュリティエージェント(Opus)・テストエージェント(Sonnet)・ドキュメントエージェント(Haiku)がそれぞれレビュー
- コーディネーターが結果を統合してレポートを生成
Netflixは、Managed Agentsを使って「数百のビルドにまたがるログ分析」を実行しているとAnthropicが紹介しています。
シナリオ3:繰り返しタスクの学習と最適化
dreamingを使って、毎日・毎週繰り返すタスクの効率を自動で改善していく構成です。
- 毎週の定型レポート作成で、過去に失敗したフォーマット変換・データ取得パターンを記憶
- 次回実行時にはあらかじめ回避策を適用するため、エラー率が低下
- 運用を続けるほどエージェントが賢くなる
Claude Coworkでの業務委任に興味がある方は、こちらの記事もあわせて参考にしてみてください。

Claude Coworkとは?料金・使い方・インストール方法を徹底解説【プラン早見表付き】
まとめ
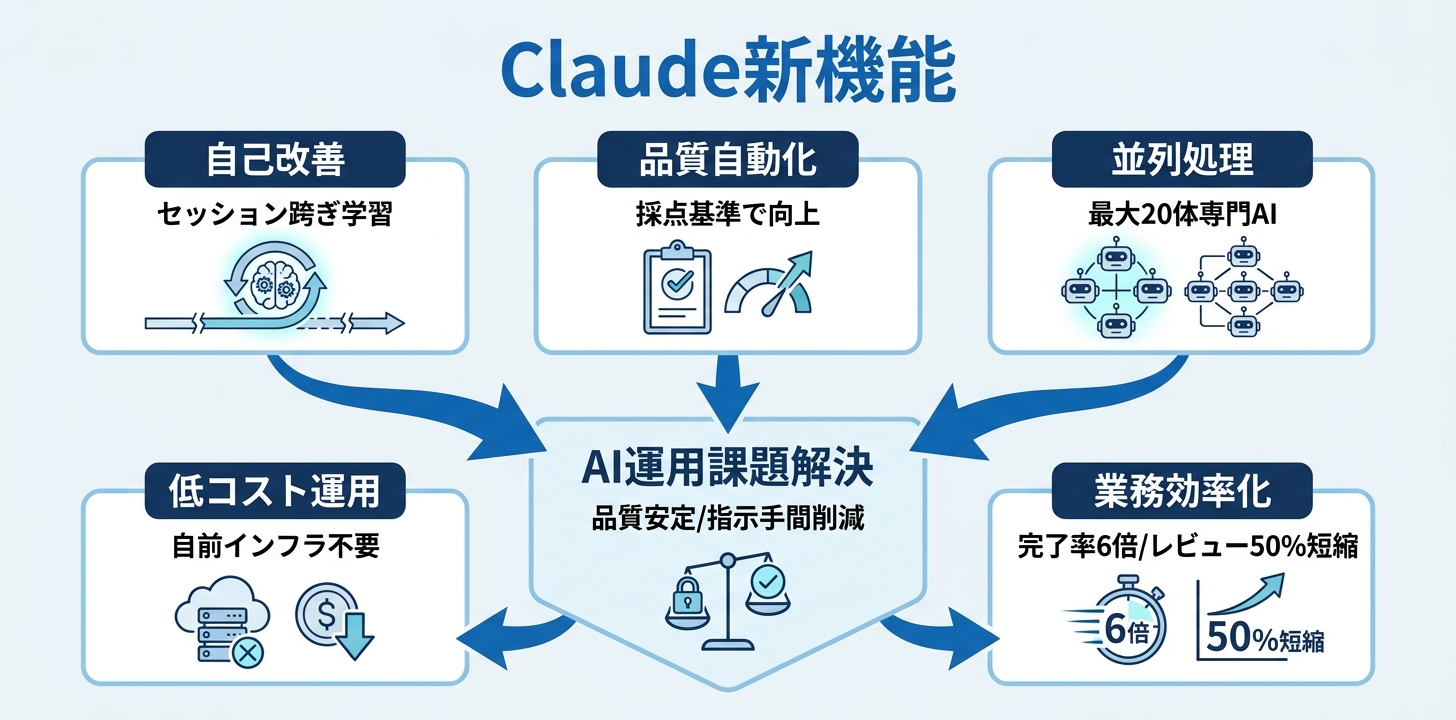
Claude Managed Agentsに追加されたdreaming・outcomes・multiagentの3機能は、AIエージェントの運用における「品質」「学習」「並列処理」の3つの課題に正面から答えるものです。
- dreaming: セッションを跨いでエージェントが自己改善する(リサーチプレビュー)
- outcomes: 採点基準に基づいて自動で品質を上げる。成功率は最大+10ポイント(リサーチプレビュー)
- multiagent: 最大20体の専門エージェントが並列で動く(リサーチプレビュー)
- 料金: 1時間のOpusセッションが約$0.70。自前インフラ構築は不要
- 導入実績: Harvey完了率約6倍、Wisedocsレビュー50%短縮(いずれもAnthropicの公式発表)
「AIエージェントに仕事を任せたいけど、品質が安定しない」「毎回同じ指示を出すのが面倒」と感じているあなたには、まさに待っていた機能だと思います。3機能はいずれもリサーチプレビュー段階のため、まずはAnthropicへアクセスリクエストを出して、小さなタスクから試してみてください。
組織全体でAIエージェントの活用を進めたい方は、デジライズの法人向けAI研修もぜひご活用ください。

この記事の著者 / 編集者

