





「ChatGPTやClaudeにお願いしているけど、毎回答えの質がバラバラ」
「プロンプトのテンプレを使ってみたけど、いまいちしっくりこない」
もしそう感じているなら、原因はプロンプトの「書き方」ではなく「設計」にあるかもしれません。
2025年5月、AnthropicはサンフランシスコのCode with Claudeイベントで「Prompting 101」というワークショップを公開しました。ここで示されたのが、プロンプトを10の要素に分解して段階的に組み立てるフレームワークです。
実演では、同じタスクに対してプロンプトをV1からV5まで5段階で改善。最初は明らかに間違った回答を返していたClaudeが、V5では正確な判定を出せるようになる過程が示されました。
この記事では、このフレームワークの全体像と実務での使い方を解説していきます。
今なら、生成AIの基礎知識から社内導入の6ステップ・定着のポイントまでを1冊にまとめた「はじめての生成AI社内導入ガイド」を無料で配布中!何から始めればいいか分からない方でも、これ1冊で導入の流れがつかめます。

目次
Anthropic公式「Prompting 101」とは
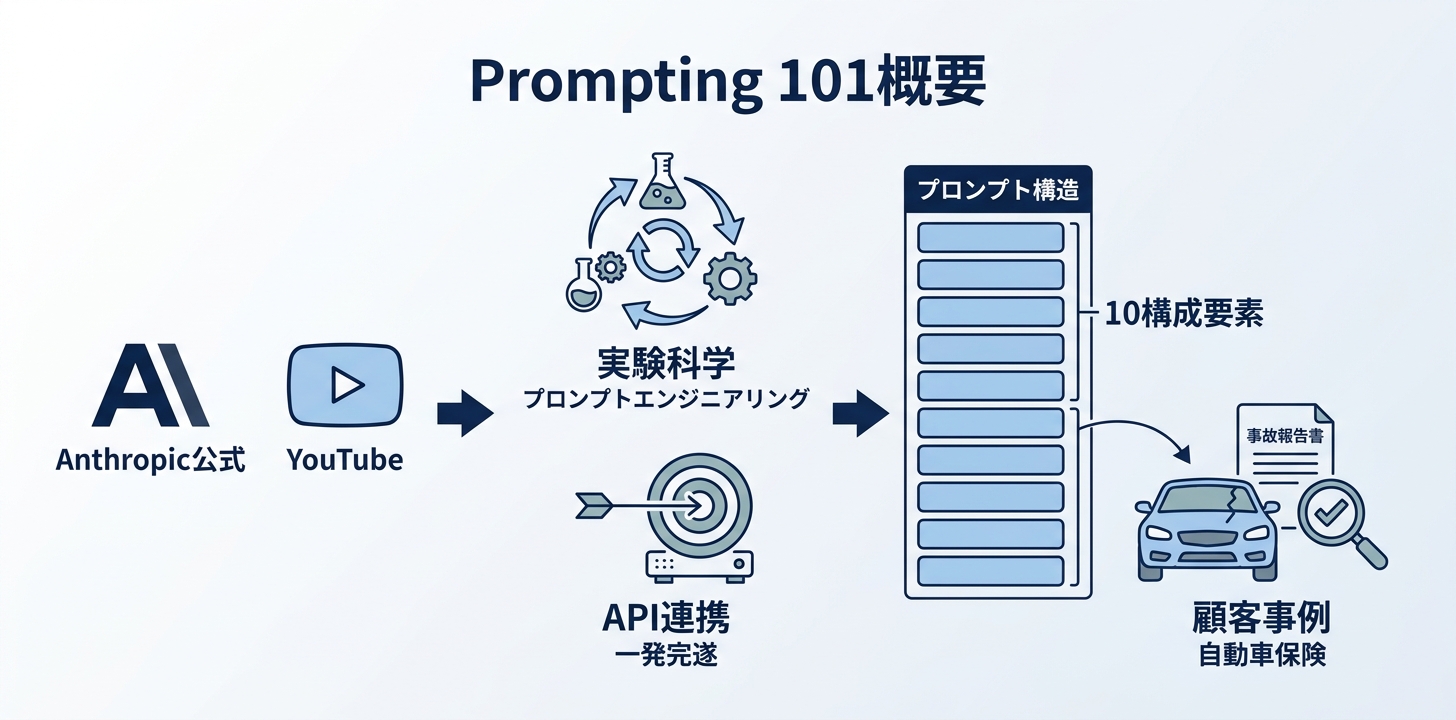
「Prompting 101」は、AnthropicのApplied AIチームに所属するHannahとChristianが、Code with Claude 2025イベント(サンフランシスコ、2025年5月)で行ったワークショップです。約25分のセッションで、YouTubeで全編が公開されています(動画リンク)。
セッションの冒頭で強調されたのは、プロンプトエンジニアリングは「反復的な実験科学」であるという考え方です。
普段私たちがAIとやり取りするとき、チャットで会話するように書くことが多いと思います。ただ、業務でAPIを使って1回のリクエストで正確な結果を出す場合は、話が変わります。セッションでは「1回のメッセージでClaudeにタスクを完遂させる」ために、プロンプトをどう構造化するかが実演されました。
実演で使われたのは、Anthropicが実際に支援した顧客事例にインスパイアされたシナリオです。具体的には、スウェーデンの自動車保険会社で事故報告書をClaudeに判定させるという課題。このリアルな題材をもとに、プロンプトの「10の構成要素」が紹介されました。
プロンプトの10要素 — 全体マップ
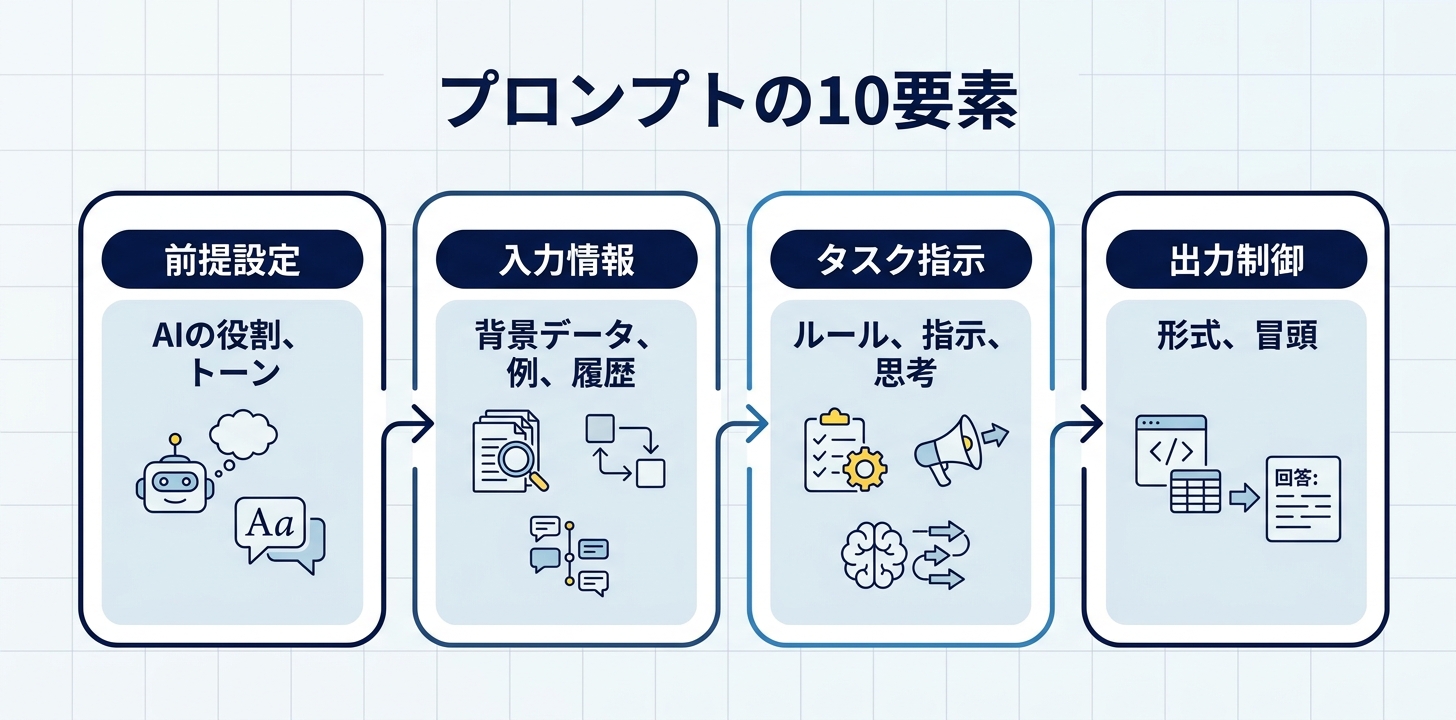
Prompting 101で紹介された10要素を一覧にまとめます。
| No. | 要素(英語名) | 日本語の意味 | ひとことで言うと |
|---|---|---|---|
| 1 | Task context | タスクの文脈 | 「あなたは○○を担当するAIです」 |
| 2 | Tone context | トーンの指定 | 丁寧語?箇条書き?専門用語OK? |
| 3 | Background data | 背景データ | 分析対象の資料やドキュメント |
| 4 | Detailed task description & rules | 詳細なルールと制約 | 「○○の場合は△△するな」 |
| 5 | Examples | 入出力の例 | 「こう聞かれたらこう答える」のサンプル |
| 6 | Conversation history | 会話の履歴 | マルチターン時の過去やり取り |
| 7 | Immediate task description | 今回の具体的な指示 | 「この書類を分析して判定を出して」 |
| 8 | Thinking step by step | 思考ステップの指定 | 「まずAを確認→次にB→最後にC」 |
| 9 | Output formatting | 出力形式の指定 | JSON?表?タグで囲む? |
| 10 | Prefilled response | 回答の先頭を固定 | API利用時に出力の冒頭を指定 |
ここで重要なのは、10個すべてを毎回使う必要はないということです。
タスクの複雑さに応じて、必要な要素だけを段階的に追加していく。これがAnthropicの推奨するアプローチです。
実際にどう追加していくのか、次のセクションで具体例を見ていきましょう。
V1→V5で精度はこう変わる — 保険クレーム判定の実例
Prompting 101のワークショップでは、スウェーデン語の自動車事故報告書をClaudeに判定させるというタスクが実演されました。
チェックボックス式のフォームと手書きのスケッチ図がある書類を読み取り、「どちらのドライバーに過失があるか」を判定させます。母国語でない書類を分析する実務的なシナリオです。
V1 — 何も指定しない(会話風プロンプト)
この画像を分析して、何が起きたか教えてください結果: Claudeはスウェーデン語の通り名「Köpmangatan」をスキーリゾートと誤認識。事故の場所も内容も的外れな回答を返しました。
これがハルシネーション(もっともらしい嘘)です。プロンプトに文脈がないため、Claudeは「それらしい答え」を推測で組み立てるしかありません。
V2 — 役割+トーン指定を追加
V2では2つの要素を追加しました。
- Task context(要素1): 「あなたはスウェーデン語の書類を分析する保険クレーム担当者の補助AIです」
- Tone context(要素2): 「事実に基づいて回答し、確信が持てない場合は無理に判定しないこと」
結果: ハルシネーションが消え、車の事故だと正しく認識するようになりました。ただし「過失を完全には判定できない」という留保付きの回答に。情報が足りない、と正直に答えた形です。
V3 — ドメイン知識を注入
V3では、Background data(要素3)として保険フォーム固有の知識をシステムプロンプトに追加しました。
- フォームの構造: 2列構成(左=Vehicle A、右=Vehicle B)、17行のチェックボックスで運転行動を表す
- 各行の意味: 17種類のチェックボックスそれぞれが何を示しているかの説明
- 記入ルールの注意点: 人間が手書きで記入するため、Xだけでなく丸印や走り書きもある。完璧なマーキングを前提にしないこと
これらをXML形式でシステムプロンプトに組み込んでいます。
<form_structure>
スウェーデン語の自動車事故報告書。2列構成。
左列 = Vehicle A、右列 = Vehicle B。
17行のチェックボックスで事故前の行動を記録。
</form_structure>
<form_completion_rules>
人間が手書きで記入。X印のほか、丸印や走り書きの場合もある。
完璧なマーキングを前提にせず、あらゆる形式のチェックを認識すること。
</form_completion_rules>セッションでは、このようにフォームの構造が毎回同じ(変わるのは記入内容だけ)であれば、システムプロンプトに入れるのが最適だと説明されました。Claudeが毎回フォームの読み方を推測する時間がなくなり、精度が上がります。
結果: 「Vehicle Bに明らかな過失がある」と明確な判定が出ました。ドメイン知識があることで、Claudeは推測ではなく根拠に基づいた判断ができるようになったのです。
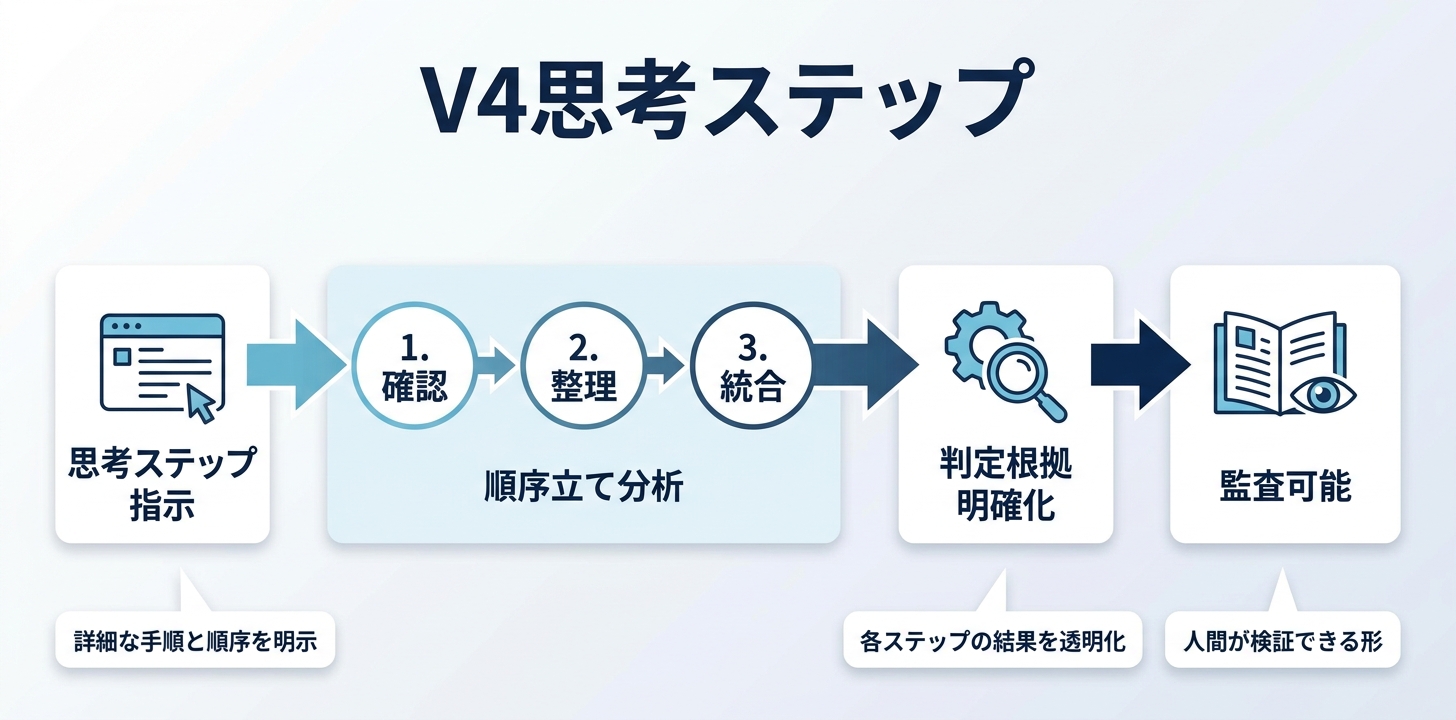
V4 — 思考ステップを指定
V4では、Detailed task description(要素4)とThinking step by step(要素8)を組み合わせて、分析の手順と順序を明示しました。
セッションで強調されたのは、分析する順序が結果に大きく影響するという点です。人間でも、意味のわからない手書きスケッチをいきなり見ても何もわかりません。先にフォームを読んで「車の事故で、こういう行動があった」と把握してからスケッチを見れば、図の意味がわかる。Claudeも同じです。
<tasks>
1. まずチェックボックスフォームを注意深く確認する。各ボックスがチェックされているか1つずつ確認する
2. フォームから読み取れた証拠をまとめる
3. フォームの情報を踏まえた上で、手書きスケッチを分析する
4. すべての証拠を統合して最終判定を出す
</tasks>結果: Claudeは各チェックボックスを1つずつ「チェックあり/なし」と確認して見せるようになりました。判定の根拠が透明化し、人間が監査できる形になっています。
V5 — 出力形式を固定
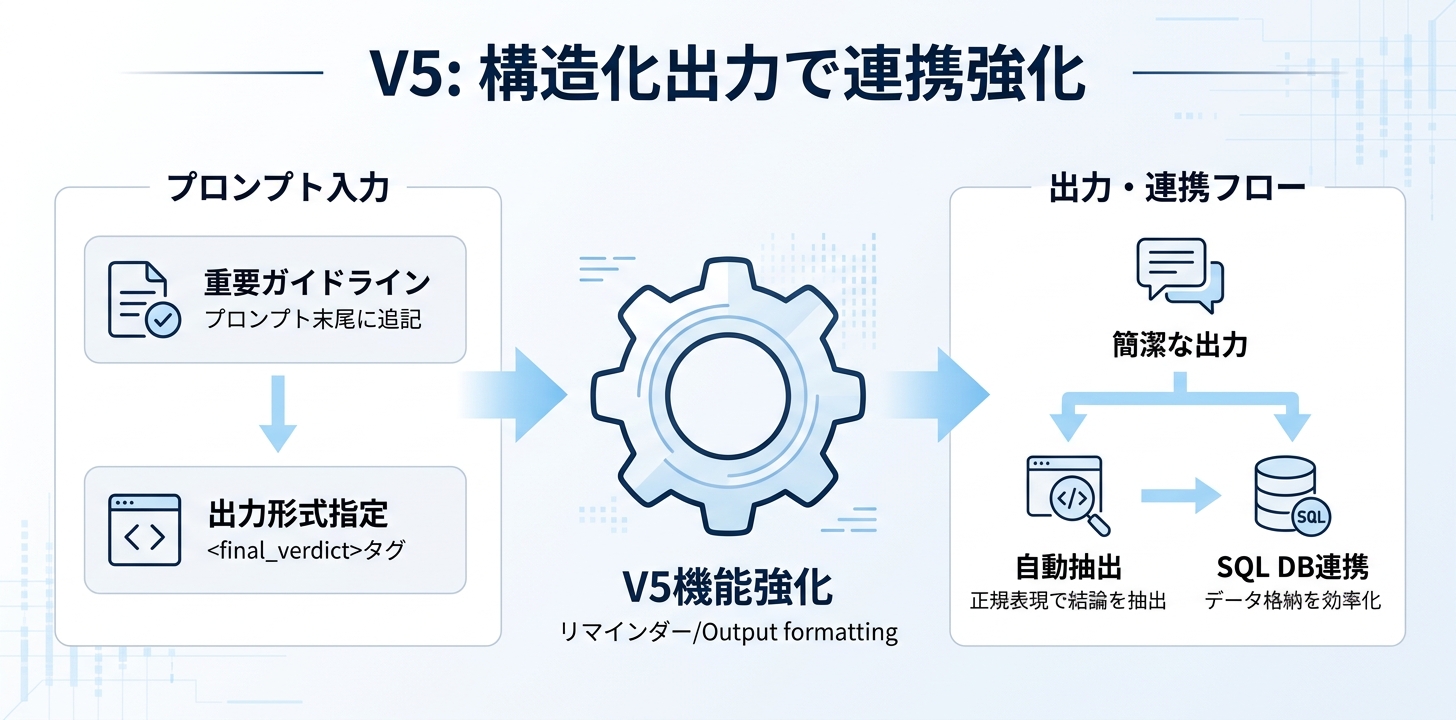
V5では、重要事項のリマインダー(要素7の応用)とOutput formatting(要素9)を追加しました。
まず、プロンプトの末尾に「重要ガイドライン」セクションを設け、要約は正確かつ簡潔であること、分析データ以外の情報に基づく判定をしないことなど、核心的なルールを再度強調します。
その上で、最終判定を
結果: 出力が簡潔になり、システムが正規表現で結論を自動抽出できる形式になりました。セッションでは「データエンジニアにとっては、前段の推論過程より最終判定をSQLデータベースに格納できる形で受け取ることが重要」と説明されています。
V1→V5の変化を整理する
| バージョン | 追加した要素 | 変化 |
|---|---|---|
| V1 | なし | ハルシネーションが発生 |
| V2 | 役割定義+トーン指定 | 嘘は消えたが判定を避ける |
| V3 | ドメイン知識の注入 | 明確な判定が出るようになる |
| V4 | 分析手順と順序の指定 | 判定根拠が透明化する |
| V5 | 出力形式の固定 | システム連携が可能になる |
V1からV5まで、プロンプトの「長さ」が増えたのではなく、必要な要素が段階的に加わったのがポイントです。
10要素の使い方 — 業務で効く6つのポイント
10要素のうち、日常業務で特に効果が大きいのは以下の6つです。残りの4つ(Conversation history、Immediate task、Prefilled response、トーン指定)は場面に応じて使い分ければ十分です。
1. Task context — 最初の1行で「誰として何をするか」を宣言する
プロンプトの冒頭で役割と目的を明確にするだけで、回答の方向性が安定します。
| 改善前 | 改善後 |
|---|---|
| この報告書をまとめてください | あなたは社内の業務改善コンサルタントです。以下の月次報告書を読み、経営層向けに要点を3つにまとめてください |
「誰として」を入れることで、Claudeは出力の粒度・専門性・トーンを自動的に調整します。
2. Background data — 「知らない情報」はプロンプトに入れる
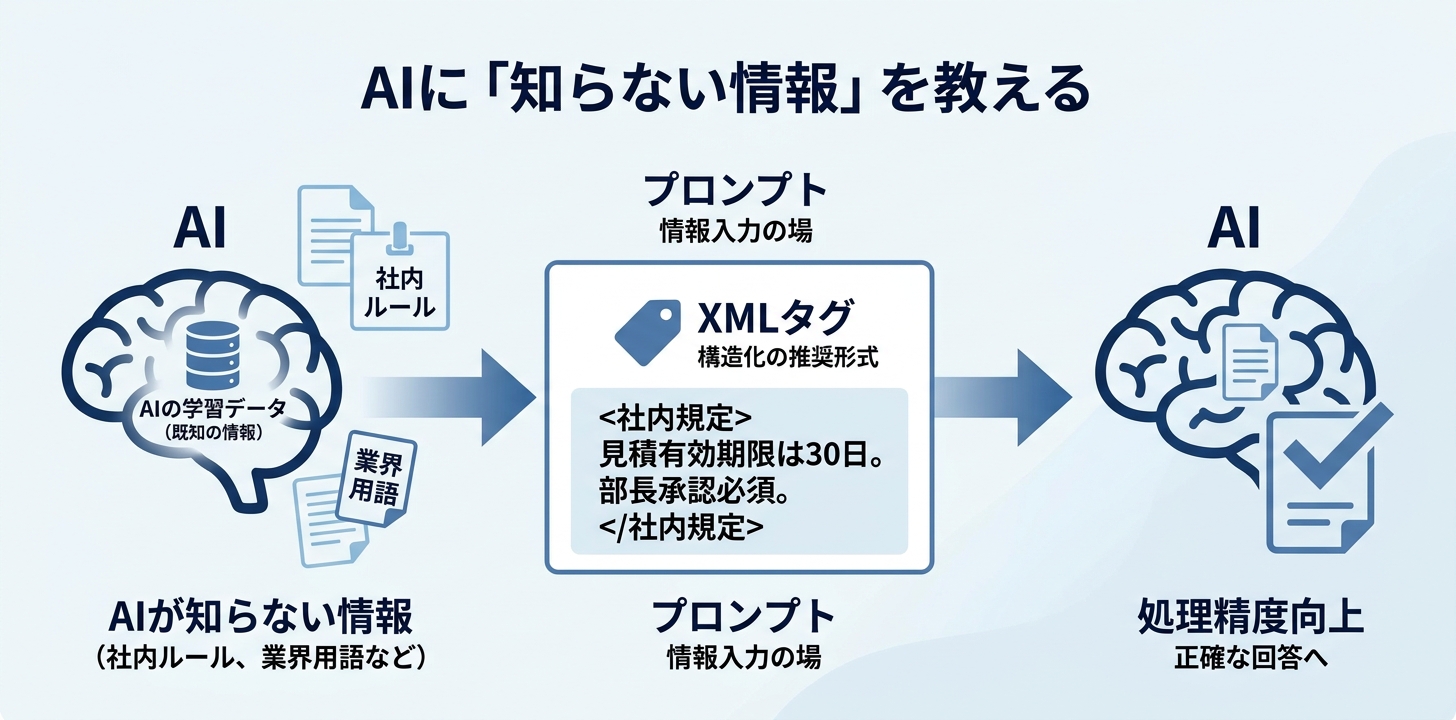
AIは学習データにない情報を知りません。社内ルール、業界固有の用語、独自のフォーマットなどは、プロンプトの中に含める必要があります。
V3で劇的に精度が上がったのは、まさにこの原理です。Claudeは保険フォームの読み方を知らなかったから推測した。フォームの構造を教えたら正確に読めるようになった。
XMLタグを使って構造化するのがAnthropicの推奨する方法です。セッションでも「ClaudeはXMLタグによる構造化を好む。タグ名で中身の意味を指定できるので、プロンプトの後半で情報を参照しやすくなる」と説明されています。
<company_rules>
見積もりの有効期限は発行日から30日間。
100万円以上の案件は部長承認が必要。
</company_rules>3. Detailed rules — 「やってはいけないこと」を明示する
AIは指示がなければ、最も確率の高い出力を返します。「やってはいけないこと」を明示しないと、意図しない振る舞いをすることがあります。
効果的なルールの書き方のコツは、条件と行動をセットにすることです。
- 数字の根拠が不明な場合は「要確認」と明記すること
- 専門用語を使う場合は括弧内に日本語の説明を入れること
- 推測に基づく情報と事実に基づく情報は明確に区別することV2で「確信が持てない場合は無理に判定しないこと」とトーン指定を追加しただけでハルシネーションが消えたのは、このルール設定の効果と共通する原理です。
4. Examples — 入出力ペアで「正解の形」を見せる
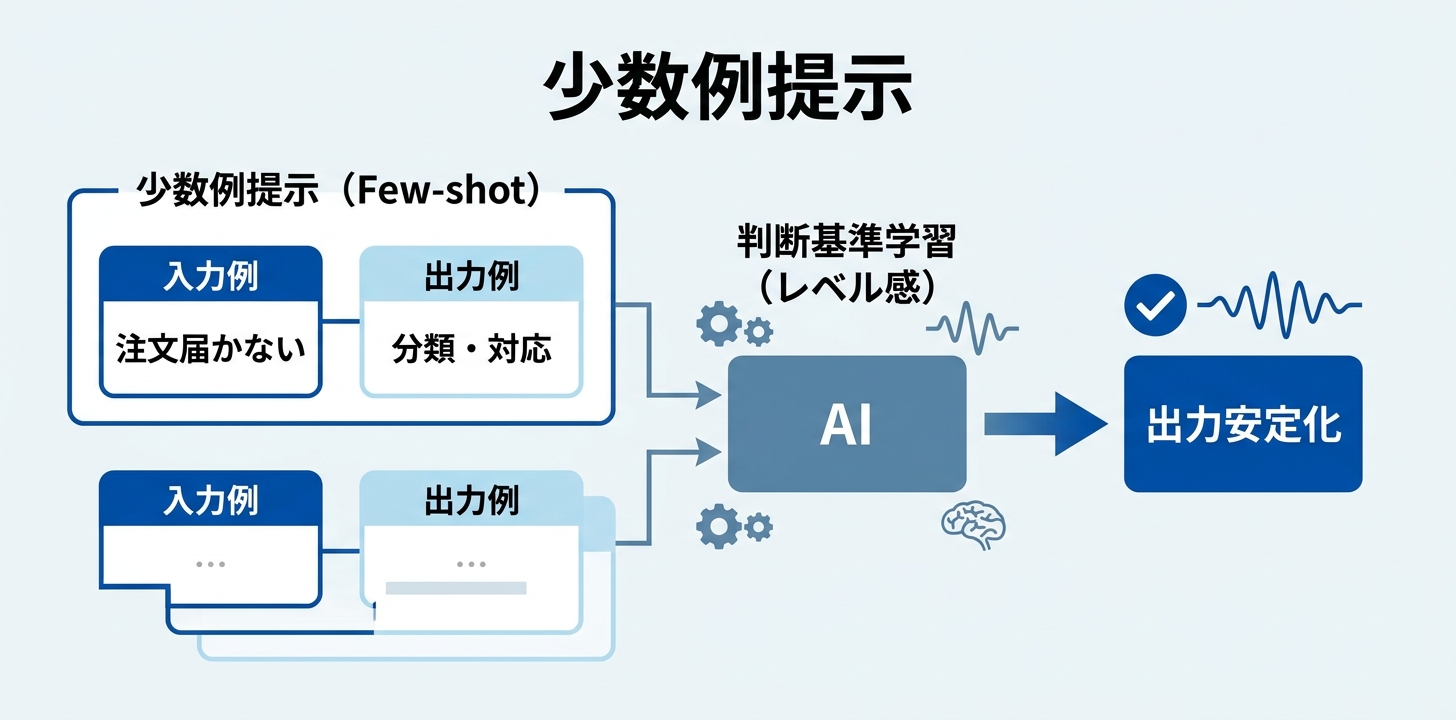
Few-shot(少数例提示)と呼ばれるテクニックです。「こういう入力にはこう答える」の具体例を1〜3組見せることで、出力品質が安定します。
<examples>
<example>
<input>顧客からのクレーム: 「注文した商品が届かない」</input>
<output>
分類: 配送遅延
緊急度: 中
推奨対応: 配送状況を確認し、24時間以内に顧客へ進捗を連絡
</output>
</example>
</examples>正解例を見せると、Claudeは形式だけでなく判断基準のレベル感も学習します。
セッションでは、画像をbase64エンコードして例に含めることも可能で、本番環境では数十〜数百の例を含めることもあると紹介されました。判断が難しいグレーゾーンの事例こそ、例として追加する価値が高いという考え方です。
5. Thinking step by step — 分析の手順を指定する
複雑な判断が必要なタスクでは、「まず○○を確認→次に△△を分析→最後に□□を判定」と手順を明示すると精度が上がります。
これはV4で使われたテクニックで、効果は2つあります。
- 精度向上: 1つずつ段階を踏むことで、情報を見落としにくくなる
- 監査可能性: なぜその結論に至ったかを追跡できる
特にClaudeのExtended Thinking機能と組み合わせると強力です。Extended Thinkingで一度Claudeの推論経路を観察し、その手順をプロンプトの
6. Output formatting — 出力形式を固定する
回答をJSON、表、XMLタグ囲みなどの決まった形式で出すよう指定すると、後工程での処理が楽になります。
以下の形式で出力してください:
<analysis>
<summary>要約をここに記載</summary>
<risk_level>高/中/低</risk_level>
<action_items>
- アクション1
- アクション2
</action_items>
</analysis>出力形式の指定はV5で追加された最後のピースです。人間が読む段階ではなくても、結果をExcelに流し込む、別のシステムに渡す、レポートに自動転記するといった業務フローを考えると、最初から形式を決めておく方が効率的です。
よくある「もったいないプロンプト」の改善パターン
実際にありがちなパターンと改善例を3つ紹介します。
パターン1: 丸投げ型
| Before | After |
|---|---|
| この議事録をまとめてください | あなたはプロジェクトマネージャーの補佐です。以下の議事録から、(1)決定事項、(2)未決事項、(3)次回までのアクションアイテムを抽出し、表形式でまとめてください |
追加した要素: Task context(要素1)+ Output formatting(要素9)
パターン2: 背景知識なし型
| Before | After |
|---|---|
| このアンケート結果を分析してください | 以下はBtoB SaaS企業の解約防止アンケートです。回答者は契約から6ヶ月以内のユーザーで、5段階評価のCSATスコアとフリーコメントが含まれます。解約リスクの兆候を特定し、改善アクションを提案してください |
追加した要素: Task context(要素1)+ Background data(要素3)
パターン3: 出力バラつき型
<!-- Before: 毎回違うフォーマットで返ってくる -->
顧客の問い合わせを分類してください
<!-- After: 形式を固定して安定させる -->
あなたはカスタマーサポートの一次対応を補助するAIです。
以下の問い合わせを分類してください。
<rules>
- 分類カテゴリは「技術的問題」「料金・請求」「機能リクエスト」「その他」の4つ
- 判断に迷う場合は「その他」に分類し、理由を添える
</rules>
<output_format>
分類: [カテゴリ名]
緊急度: [高/中/低]
根拠: [判断理由を1文で]
</output_format>追加した要素: Task context(要素1)+ Detailed rules(要素4)+ Output formatting(要素9)
Extended ThinkingとPrefillの最新事情
ワークショップで紹介されたテクニックのうち、Prefill(要素10)についてはClaude 4以降で扱いが変わっています。
Prefill(回答の先頭固定)
PrefillはAPIでClaudeの回答の先頭部分を指定するテクニックで、JSON出力を{で強制的に始めさせるといった用途がありました。
ただし、Claude 4.6以降ではPrefillは非推奨になっています。代わりに、Output formatting(要素9)で出力形式を明示する方法が公式に推奨されています。
ワークショップは2025年5月時点の内容であるため、最新のClaude 4環境では要素9(出力形式の指定)で代替するのが正しいアプローチです。
Extended Thinking(拡張思考)
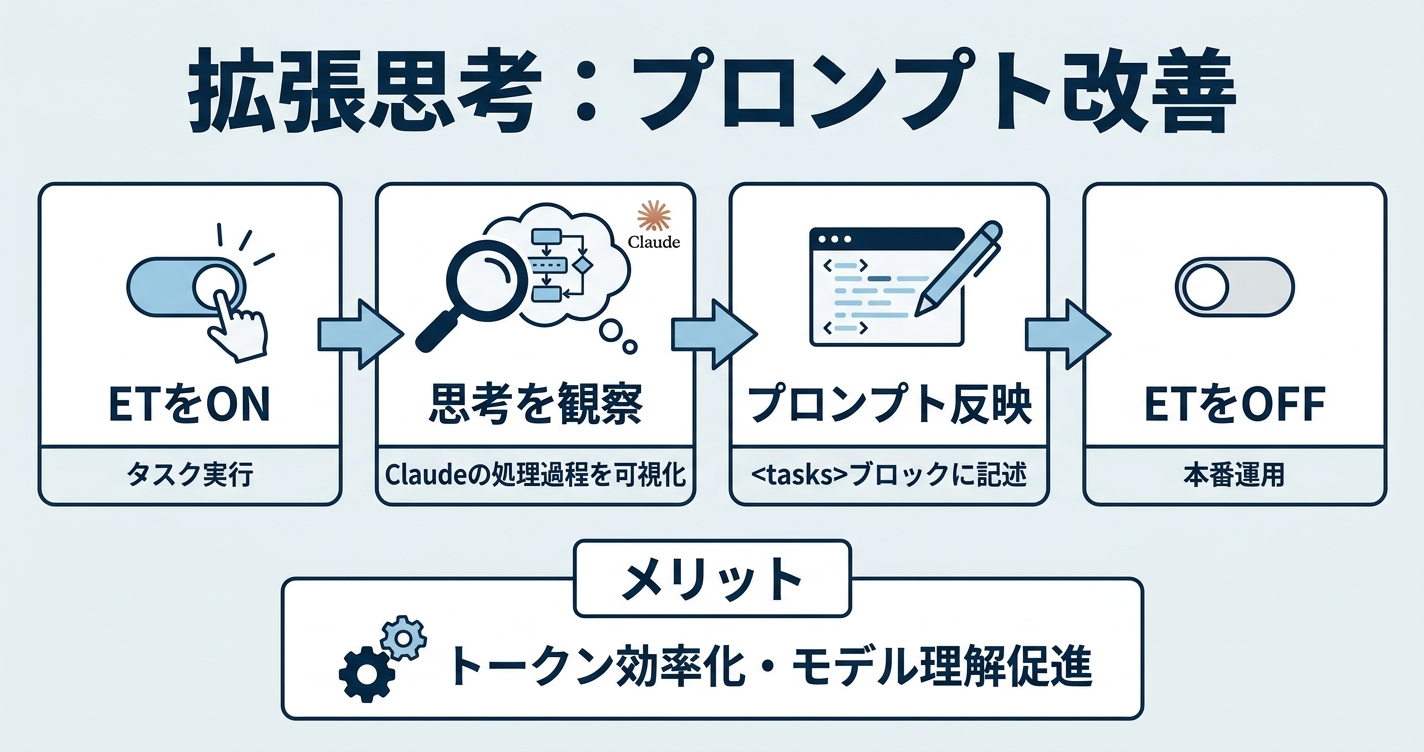
Extended Thinkingは、Claudeに「考える過程」を可視化させるAPI機能です。ワークショップではこの機能を「プロンプトエンジニアリングの松葉杖(crutch)」と表現していました。つまり、完成したプロンプトに常時組み込むものではなく、プロンプトを改善するための補助ツールです。
- Extended ThinkingをONにしてタスクを実行する
- thinking tagsの中身を読み、Claudeがデータをどう処理しているかを観察する
- その手順をプロンプトの
- 本番ではExtended ThinkingをOFFにして運用する
セッションでは「人間の直感を持たないモデルが、データにどうアプローチしているかを理解できる」「手順をシステムプロンプトに組み込む方がトークン効率も良い」と説明されています。
Claude 4.6以降では、Adaptive Thinking(thinking: {type: "adaptive"})というより柔軟な仕組みも導入されています。
まとめ — 今日から始める3ステップ
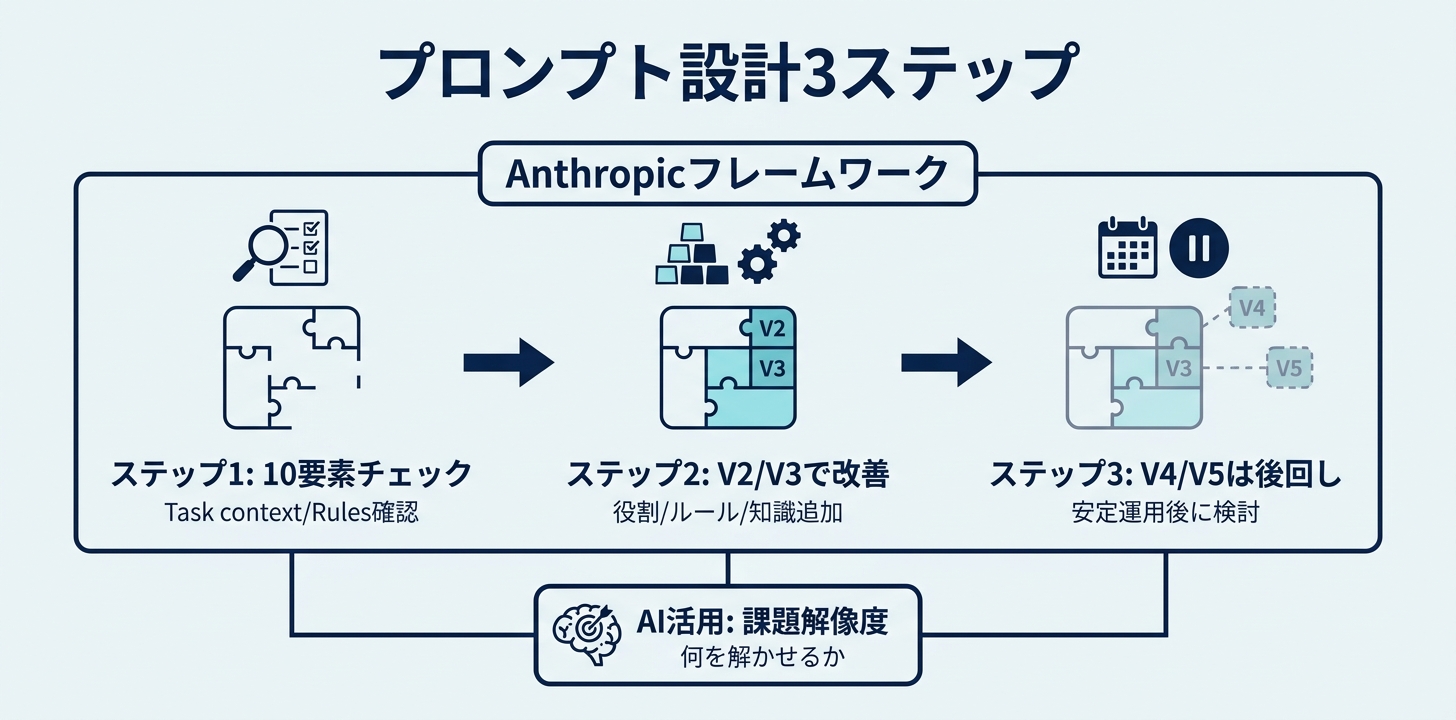
Anthropic公式が提示したプロンプト設計のフレームワークを整理すると、実践のポイントは3つです。
ステップ1: 今のプロンプトを10要素でチェックする
普段使っているプロンプトに、10要素のうちどれが入っていてどれが欠けているかを確認する。多くの場合、Task contextとRulesが抜けています。
ステップ2: V2とV3を最優先で追加する
まずはTask context(役割定義)とRules(ガードレール)を追加してV2相当に。次にBackground data(ドメイン知識)を足してV3相当に。この2段階だけで、出力品質は目に見えて変わります。
ステップ3: V4・V5は「安定運用」が必要になってから
思考ステップの指定(V4)や出力形式の固定(V5)は、同じプロンプトを繰り返し使う場面で真価を発揮します。まずはV3までの改善を実感してから、必要に応じて追加してください。
プロンプトの書き方以前に「そもそもAIに何を解かせるべきか」を考えることも重要です。この点については、こちらの記事で詳しく解説しています。

プロンプトエンジニアリングはもう不要?AIで差がつく課題解像度とワークフロー設計の考え方
生成AIを業務に取り入れたいけど、何から始めればいいかわからない——そんな方に向けた法人研修を提供しています。今回紹介したプロンプト設計のフレームワークも、研修カリキュラムに組み込まれています。

この記事の著者 / 編集者

