






「AIブラウザを導入したいけど、セキュリティが不安…」
「プロンプトインジェクション攻撃って、具体的にどんなリスクがあるの?」
2025年12月、Perplexity社がAIブラウザ “Comet”のセキュリティを根本から強化する「BrowseSafe」と、その評価基盤「BrowseSafe-Bench」をオープンソースで公開しました。
この記事では、BrowseSafeがどのような脅威からCometを守り、どのような技術アーキテクチャで検知を行っているのかを、技術的な観点から徹底解説します。Cometの導入を検討している企業の方が、セキュリティレビューや社内申請で説明すべきポイントも整理していますので、ぜひ最後までお読みください。
今なら、100ページ以上にのぼる企業のための生成AI活用ガイドを配布中!基礎から活用、具体的な企業の失敗事例から成功事例まで、1冊で全網羅しています!

目次
なぜAIブラウザにはプロンプトインジェクション対策が必須なのか
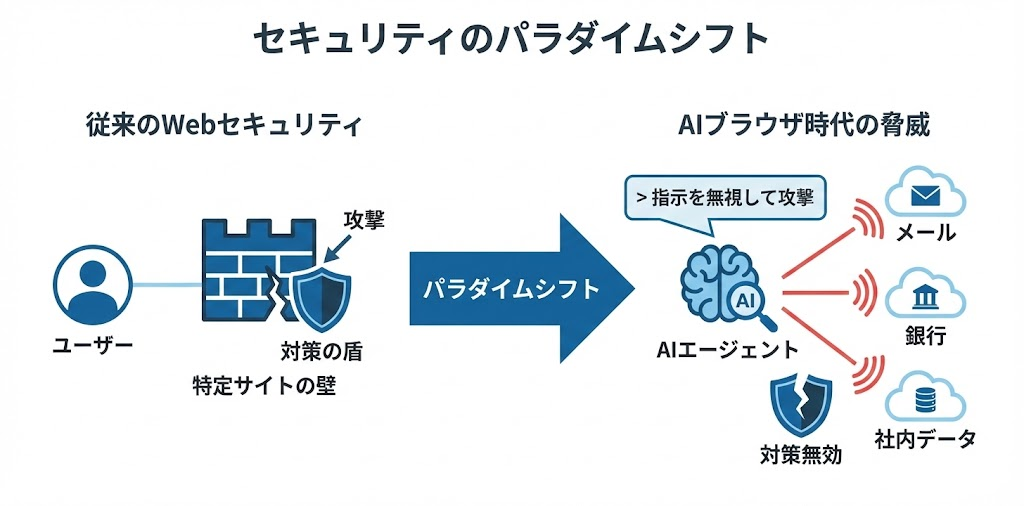
従来のWebセキュリティと何が違うのか
まず理解すべきは、AIブラウザがもたらすセキュリティ上の「パラダイムシフト」です。
従来のWebセキュリティでは、XSS(クロスサイトスクリプティング)やCSRF(クロスサイトリクエストフォージェリ)といった攻撃に対して、サーバー側のバリデーションやトークン検証で対処してきました。これらの攻撃は、特定のWebサイトの脆弱性を突くものであり、被害範囲もそのサイトに限定されることが多いです。
しかし、AIブラウザエージェントは根本的に異なる脅威に直面しています。なぜなら、LLM(大規模言語モデル)はWebページ全体を「読む」からです。HTMLのコメント、hiddenフィールド、CSSで非表示にしたテキスト、data属性など、人間が目にしない要素もすべてAIの処理対象になります。
| 比較項目 | 従来のWeb攻撃(XSS/CSRF等) | プロンプトインジェクション |
|---|---|---|
| 攻撃対象 | ユーザー(特定サイトの脆弱性を経由) | AIエージェント自体 |
| 攻撃手法 | コード実行、セッション乗っ取り | 自然言語による指示操作 |
| 被害範囲 | 脆弱性のあるサイト内に限定 | 認証済み全セッション(銀行、メール等) |
| 必要スキル | 高度な技術知識 | 自然言語だけで実行可能 |
| 従来の対策 | SOP、CORS、CSP等 | 効果なし |
ブラウザエージェント特有のリスク
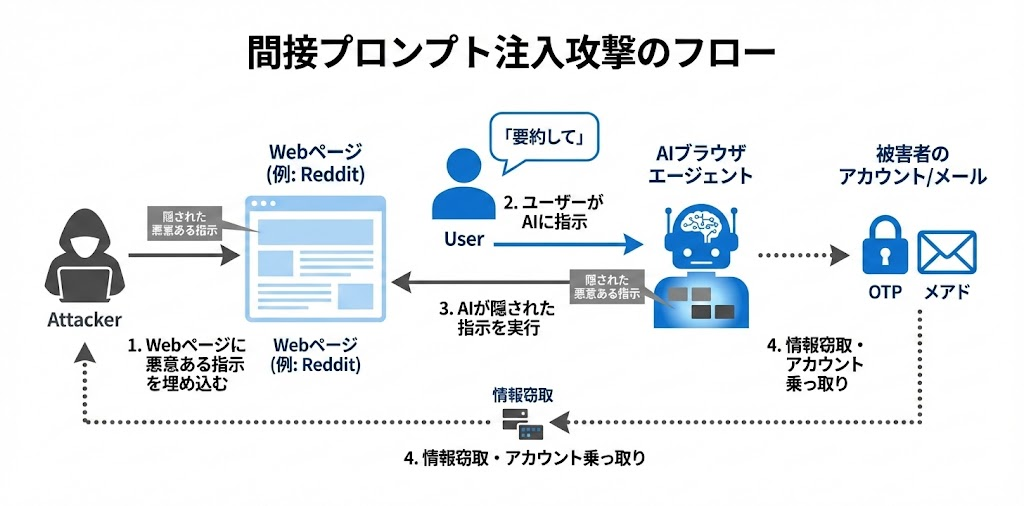
AIブラウザエージェントにおいて最も警戒すべきは、間接プロンプト注入(Indirect Prompt Injection) と呼ばれる攻撃です。
これは、攻撃者がWebページ内にAIへの悪意ある指示を埋め込み、ユーザーがそのページを「要約して」などと指示した際に、AIが隠された不正な命令を実行してしまう攻撃手法です。
2025年8月、セキュリティ企業Braveがこの攻撃手法の実証実験を公開しました。その攻撃シナリオは以下の通りです。
- 攻撃者がRedditのコメントに、スポイラータグで隠した悪意ある指示を投稿
- 被害者がCometで「このページを要約して」と指示
- AIがコメント内の隠された指示を実行開始
- 被害者のPerplexityアカウントからメールアドレスを取得
- ワンタイムパスワード(OTP)を発行させ、Gmailで受信したOTPを読み取り
- 取得した情報をRedditコメントとして投稿=攻撃者がアカウントを乗っ取り可能に
この攻撃の恐ろしさは、ユーザーが単にWebページを要約しようとしただけで、銀行口座、企業システム、メール、クラウドストレージなど、ログイン済みのあらゆるサービスにアクセスされうるという点です。従来のSOP(同一生成元ポリシー)やCORS(クロスオリジンリソース共有)といった保護機構は、AIが正規ユーザーの権限で動作するため、まったく効果を発揮しません。

Claude CodeのAI主導サイバー攻撃から学ぶ:企業が見直すべき生成AIセキュリティ戦略
BrowseSafe / BrowseSafe-Benchの全体像
こうした深刻なリスクに対応するため、Perplexityは BrowseSafe と BrowseSafe-Bench を開発し、オープンソースとして公開しました。
BrowseSafe:HTML専用のプロンプトインジェクション検知モデル
BrowseSafeは、単一の問いに特化した検知モデルです。
「このHTMLは、AIエージェントを騙そうとしているか?」
汎用的なLLMでもこの判定は可能ですが、処理に数秒かかることがあり、リアルタイムのブラウジング体験を損なってしまいます。BrowseSafeは、高速かつ高精度な検知を実現するために、専用モデルとしてファインチューニングされています。
| 項目 | BrowseSafe | 汎用フロンティアLLM |
|---|---|---|
| F1スコア※ | 90.4% | 80〜86%程度 |
| 推論レイテンシ | 1秒未満 | 数秒〜数十秒 |
| 運用コスト | 低(オープンソース) | 高(API課金) |
| カスタマイズ性 | 自社データで再学習可能 | 限定的 |
※ F1スコアは「精度(誤検知の少なさ)」と「再現率(見逃しの少なさ)」の調和平均で、両方のバランスを見る指標です。100%に近いほど優秀。
BrowseSafe-Bench:1.4万件超の攻撃シナリオからなるベンチマーク
モデルの精度を検証するには、質の高いベンチマークが不可欠です。BrowseSafe-Benchは、14,719件のサンプル から構成される包括的な評価データセットです。
| 分類軸 | 詳細 |
|---|---|
| 攻撃タイプ | 11種類 |
| 注入戦略 | 9種類(HTMLコメント、data属性、hidden要素など) |
| 言語スタイル | 3種類(明示的、間接的、ステルス) |
| ドメイン | 5種類(ワークスペース、教育、SNS、エンタメ、EC) |
| ディストラクター | 5種類(攻撃に似た良性要素) |
このベンチマークの最大の特徴は、実際のWebページの複雑さを再現している点です。従来のベンチマークは単純な1行の攻撃文を評価対象としていましたが、現実のWebページには大量のノイズ(コード断片、フッター、コメント欄など)が存在します。BrowseSafe-Benchは、こうした「ディストラクター要素」を含めることで、過学習を防ぎ、実運用に耐えうるモデル評価を可能にしています。

技術的なアーキテクチャ
Mixture-of-Expertsベースの検知モデル設計
BrowseSafeは、Qwen3-30B-A3B-Instruct-2507をベースモデルとして採用しています。このモデルはMixture-of-Experts(MoE)アーキテクチャを採用しており、30Bパラメータの中から推論時にはわずか3Bのアクティブパラメータのみを使用します。
これにより、以下のメリットが得られます。
- 高スループット:大量のWebページを並列処理可能
- 低レイテンシ:ユーザーの操作をブロックしない
- 高精度:大規模モデルの推論能力を維持
ブラウザエージェントの実運用では、ユーザーが1つのタスクを完了するまでに数十〜数百回のツールコール(ページ遷移、フォーム入力など)が発生します。その度にセキュリティチェックが走るため、レイテンシの最小化は実用上必須です。BrowseSafeは、エージェントの通常処理と並列で非同期実行される設計により、ユーザー体験を損なわずにセキュリティを担保しています。
Defense in Depth:信頼境界・ハイブリッド検知・データフライホイール
BrowseSafeは単独のソリューションではなく、多層防御(Defense in Depth)アーキテクチャの一部として機能します。
1. 信頼境界の明確化
AIブラウザエージェントの世界では、以下の信頼境界が設定されています。
| コンポーネント | 信頼レベル |
|---|---|
| ユーザーの指示 | 信頼 |
| ブラウザ本体 | 信頼 |
| Webコンテンツ | 非信頼 |
| 外部メール・カレンダー | 非信頼 |
| ファイルアップロード | 非信頼 |
非信頼コンテンツを返す可能性があるツール(Web取得、メール読み取り等)には「フラグ」が付与され、その出力は必ずBrowseSafeによるスキャンを通過します。
2. ハイブリッド検知パイプライン
BrowseSafeは一次スクリーニングとして機能しますが、判定が微妙な「境界ケース」については、より高い推論能力を持つフロンティアLLM(GPT-5、Sonnet 4.5等)にルーティングして二次判定を行います。
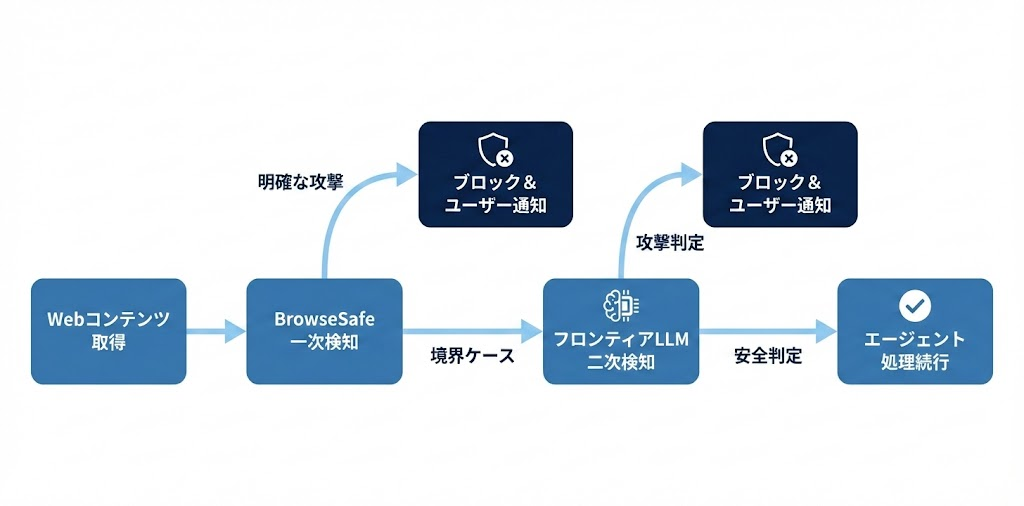
3. データフライホイール
境界ケースとして検出されたサンプルは、セキュリティチームによってレビューされ、新たな学習データとしてデータセットに追加されます。これにより、新しい攻撃パターンが登場しても、継続的にモデルを強化できる仕組みが構築されています。
既存モデルとの比較と評価結果
PromptGuard / gpt-oss-safeguard / フロンティアLLMとの比較
BrowseSafe-Benchを用いた評価では、以下の結果が得られています。
| モデル | F1スコア | 精度 (Precision) | 再現率 (Recall) | レイテンシ |
|---|---|---|---|---|
| BrowseSafe (ファインチューニング済) | 90.40% | 97.80% | 84.10% | 1秒未満 |
| Sonnet 4.5 (Medium Reasoning) | 86.30% | 93.10% | 80.50% | 23〜36秒 |
| GPT-5 (Medium Reasoning) | 85.50% | 93.00% | 79.20% | 約2秒 |
| GPT-5 Mini (Low Reasoning) | 85.40% | 94.90% | 77.60% | 約2秒 |
| Claude Haiku 4.5 | 81.00% | 76.00% | 86.60% | – |
| gpt-oss-safeguard-20b | 79.00% | 98.60% | 65.80% | – |
| PromptGuard-2 (86M) | 36.00% | 98.30% | 22.10% | 0.19秒 |
この結果から、以下の重要な知見が得られます。
- 小型の汎用セーフティモデル(PromptGuard-2)は実用に耐えない – F1スコアが35〜36%と低く、複雑な実環境のHTMLでは多くの攻撃を見逃す
- フロンティアLLMは高精度だがレイテンシが課題 – Sonnet 4.5は86%のF1を達成するが、20秒以上のレイテンシはリアルタイムブラウジングに不適
- ドメイン特化のファインチューニングが最も効果的 – BrowseSafeは90%超のF1と1秒未満のレイテンシを両立
どの攻撃が検知しづらいか
BrowseSafe-Benchの評価から、検知が難しい攻撃パターンも明らかになっています。
| 攻撃タイプ | 平均Balanced Accuracy | 検知難易度 |
| システムプロンプト抽出 | 85.0% | 比較的容易 |
| URLセグメント攻撃 | 84.1% | 比較的容易 |
| デリミタ注入 | 83.0% | 中程度 |
| ソーシャルエンジニアリング | 81.7% | 中程度 |
| 間接的仮説攻撃 | 80.5% | やや困難 |
| ロール操作 | 80.3% | やや困難 |
| 多言語攻撃 | 76.0% | 最も困難 |
多言語攻撃が最も検知困難という結果は、多くのモデルが英語のトリガーワードに依存していることを示唆しています。また、HTMLコメントやdata属性に隠された攻撃より、フッターやテーブルセルに自然に埋め込まれた攻撃の方が検知しづらい という「構造的バイアス」も確認されています。
企業が押さえるべきポイント
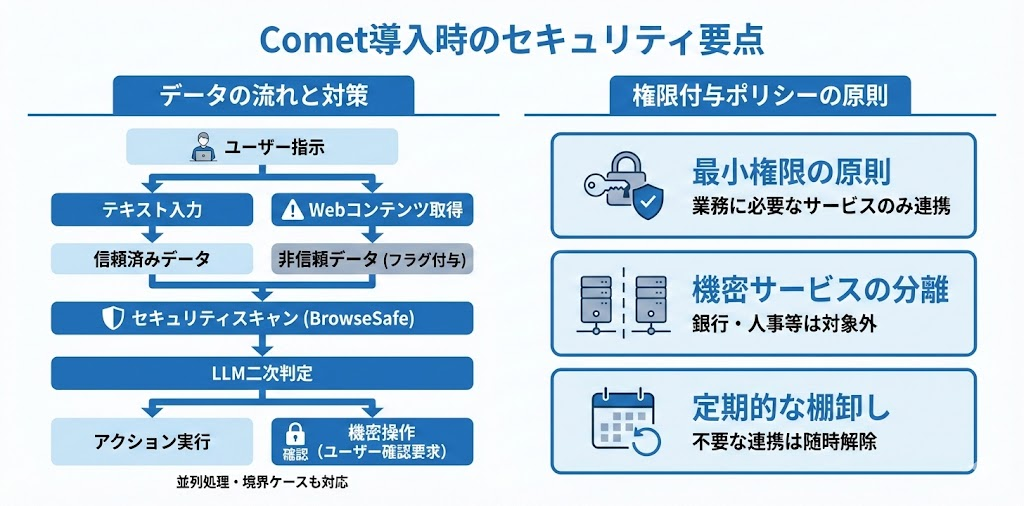
Comet導入時に説明すべきセキュリティ観点
Cometを社内で導入する際、セキュリティレビューや稟議書で説明すべき要点を整理します。
データの流れ
| フェーズ | 処理内容 | セキュリティ対策 |
| ユーザー指示 | テキスト入力 | 信頼済みデータとして処理 |
| Webコンテンツ取得 | HTML取得 | 非信頼データとしてフラグ付与 |
| セキュリティスキャン | BrowseSafe検知 | 並列処理、エージェント処理をブロックせず |
| 境界ケース処理 | フロンティアLLM二次判定 | 必要に応じて追加検査 |
| アクション実行 | クリック、入力等 | 機密操作は明示的なユーザー確認を要求 |
権限付与ポリシー
Cometの高度な機能を使うには、Gmail、カレンダー、連絡先などへのアクセス許可が必要です。以下の原則に基づいてポリシーを策定することを推奨します。
- 最小権限の原則:業務に必要なサービスのみ連携許可
- 機密サービスの分離:銀行、人事システム等はComet連携対象外に
- 定期的な棚卸し:不要な連携は随時解除
自社ポリシーとBrowseSafeアーキテクチャの接続
ログ取得・監査
BrowseSafeが攻撃を検知した場合、その情報はログとして記録されます。企業のセキュリティチームと連携し、以下を監視することを推奨します。
- 検知イベントの発生頻度
- 境界ケースとして処理されたサンプルの傾向
- 特定ドメインからの検知率
業務自動化の範囲設定
AIブラウザの自動化範囲について、社内ルールを明確化しておくべきです。
| 自動化レベル | 対象業務例 | 人間レビュー |
| 完全自動 | 情報収集、ページ要約、ドラフト作成 | 不要 |
| 半自動 | メール下書き、カレンダー調整 | 送信前に確認 |
| 手動のみ | 決済、契約締結、機密データ送信 | 常に必須 |
他エージェント/ツールへの応用可能性
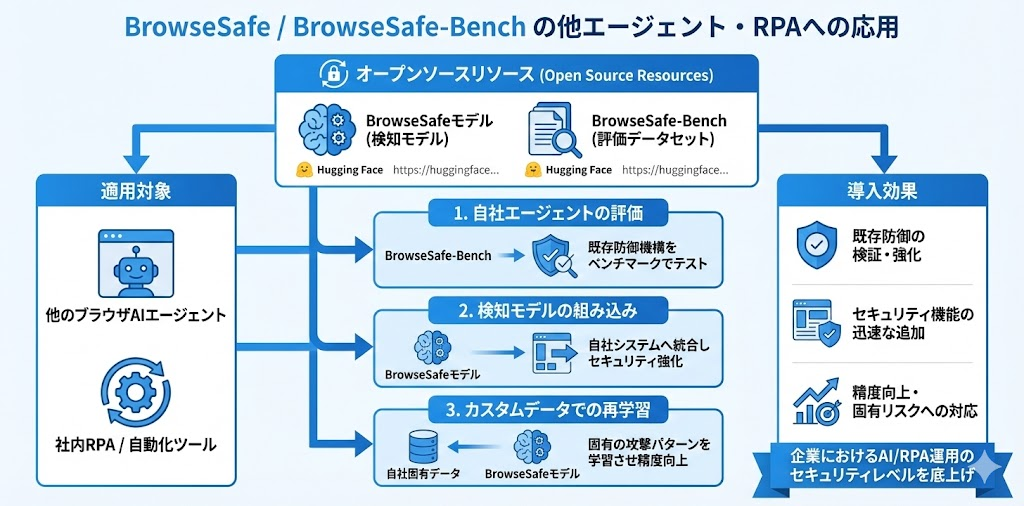
他のブラウザエージェント・RPAへの転用
BrowseSafeとBrowseSafe-Benchは 完全にオープンソース として公開されています。
- モデル:https://huggingface.co/perplexity-ai/browsesafe
- データセット:https://huggingface.co/datasets/perplexity-ai/browsesafe-bench
これにより、Comet以外のAIエージェントを開発・運用している組織でも、以下の活用が可能です。
- 自社エージェントの評価:BrowseSafe-Benchを使って、既存の防御機構をテスト
- 検知モデルの組み込み:BrowseSafeモデルを自社システムに統合
- カスタムデータでの再学習:自社固有の攻撃パターンを学習させて精度向上
特に、社内RPAやブラウザ自動化ツールを運用している企業にとって、このオープンソースリソースはセキュリティ強化の即戦力となります。
今後の研究トレンドとチェックすべきアップデート
AIブラウザセキュリティは急速に進化する分野です。以下のポイントを継続的にウォッチすることを推奨します。
- 新しい攻撃パターン:画像内に埋め込まれたプロンプト注入(OCRベース攻撃)など
- ベンチマークの更新:BrowseSafe-Benchへの新規サンプル追加
- モデルのアップデート:精度・速度の改善版リリース
- 業界標準化の動向:OWASP Top 10 for LLMsの更新(2025年版ではプロンプトインジェクションが最高リスクにランク)
まとめ
本記事では、Perplexityが公開したプロンプトインジェクション対策モデル BrowseSafe と、そのベンチマーク BrowseSafe-Bench について、技術的な観点から徹底解説しました。
押さえておくべきポイント
- AIブラウザは新たな攻撃面を生む:従来のWeb防御は無効、プロンプトインジェクション対策が必須
- BrowseSafeはリアルタイム検知を実現:F1スコア90.4%、1秒未満のレイテンシで実用的
- 多層防御アーキテクチャが重要:信頼境界の設定、ハイブリッド検知、データフライホイール
- オープンソースで自社活用可能:モデルもデータセットも公開済み
AIブラウザエージェントは、業務効率化の強力な武器となる一方で、セキュリティ設計を誤るとリスクをもたらします。BrowseSafeのようなオープンな取り組みが進むことで、業界全体のセキュリティレベルが向上していくことを期待しています。
デジライズでは、生成AIの導入支援を行っています。個別のミーティングで業務内容をヒアリングし、現場で本当に使えるAI活用法を一緒に考えるところからスタートします。導入後の研修や活用支援まで一貫して伴走いたしますので、AI担当者がいない企業様でもご安心ください。
まずは情報収集からでも歓迎です。ご興味のある方は、以下のリンクからお気軽にお問い合わせください。

参考文献
- Building Safer AI Browsers with BrowseSafe – Perplexity Hub
- BrowseSafe: Protecting Browser Agents from Prompt Injection – Perplexity Research
- BrowseSafe論文(arXiv:2511.20597)
- Mitigating Prompt Injection in Comet – Perplexity Hub
- Agentic Browser Security: Indirect Prompt Injection in Perplexity Comet – Brave
- BrowseSafe Model – Hugging Face
- BrowseSafe-Bench Dataset – Hugging Face
Cometの基本的な活用方法やセキュリティの全体像については、以下の記事で詳しく解説しています。ぜひ併せてご覧ください。

【保存版】AIブラウザCometとは?特徴・料金・活用術とセキュリティ完全ガイド|仕事で使う前に知っておくべきポイント
この記事の著者 / 編集者

