






OpenAIが、リアルタイム音声・テキスト対話API「Realtime API」の大型アップデートを発表しました。
2026年5月7日、高い推論性能を備えた最新モデル gpt-realtime-2、多言語のリアルタイム翻訳に対応した gpt-realtime-translate、ストリーミング文字起こし専用の gpt-realtime-whisper の3モデルが一挙に追加されています。同時に、ベータ版のエンドポイントは廃止され、GA(正式版)への移行が必要になっています。
Realtime APIは、カスタマーサポートの自動音声応答、リアルタイム多言語翻訳、音声エージェントの構築など、従来のテキストAPI(Chat Completions / Responses API)では対応しにくかった「即時性のあるAI音声対話」を実現するAPIです。
この記事では、Realtime APIの全体像から、実際にPythonで接続してテキスト対話・Function Calling・音声ファイル生成まで動かした結果、料金体系、コールセンターなどの具体的な活用シーンまで、一通りの情報をまとめました。

目次
Realtime APIとは|従来のAPIと何が違うのか
Realtime APIは、OpenAIが提供するリアルタイム音声・テキスト対話APIです。通常のテキストAPI(Chat Completions / Responses API)が「リクエスト→レスポンス」の一往復で完結するのに対して、Realtime APIはWebSocketで常時接続し、ストリーミングで双方向にやり取りする設計になっています。
テキストAPI との違い
| 比較項目 | テキストAPI(Responses API等) | Realtime API |
|---|---|---|
| 接続方式 | HTTP(リクエスト/レスポンス) | WebSocket / WebRTC / SIP |
| 音声処理 | 別途Whisper + TTSが必要 | 音声入出力を直接処理 |
| レイテンシ | 数百ms〜数秒 | 数百ms以下(ストリーミング) |
| セッション | ステートレス | 長時間の持続セッション(接続管理が必要) |
| 対話の割り込み | 不可 | 発話中の割り込みに対応 |
従来の音声AIアプリを作ろうとすると、「音声→Whisperで文字起こし→テキストAPIで回答生成→TTSで音声合成」という3段パイプラインが必要でした。Realtime APIはこれを単一のWebSocket接続で処理します。音声の入力から応答までを単一接続で低遅延に処理できるため、パイプラインによる遅延がなくなり、自然な会話のテンポが実現できます。
また、Realtime APIは「リアルタイム対話」だけでなく、テキストを入力してストリーミング音声を受け取り、アプリ側でファイル保存するTTS(テキスト読み上げ)的な使い方もできます。後述のデモで実際に音声を生成しているので、参考にしてみてください。
3つの接続方式
| 方式 | 用途 | 特徴 |
|---|---|---|
| WebRTC | ブラウザ・モバイルアプリ | クライアント向け推奨。エフェメラルトークンでAPIキーを保護可能 |
| WebSocket | サーバーサイド処理 | バックエンド統合に最適。本記事のデモでも使用 |
| SIP | VoIP電話・PBX連携 | 既存の電話システムにAI音声エージェントを接続 |
2026年5月7日アップデート|3つの新モデルが追加
2026年5月7日のアップデートで、Realtime APIに以下の3モデルが追加されました。同時にベータ版エンドポイントが廃止され、既存ユーザーはGA版への移行が必要です。
gpt-realtime-2 — 最新フラッグシップ
高い推論性能を備えた音声エージェント向けの最新モデルです。コンテキストウィンドウは32,000トークン。テキスト・音声・画像の3つの入力モダリティに対応しています。
前世代のgpt-realtimeおよびgpt-realtime-1.5と比較して、指示への従行率やFunction Calling精度が向上しています。
gpt-realtime-translate — リアルタイム多言語翻訳
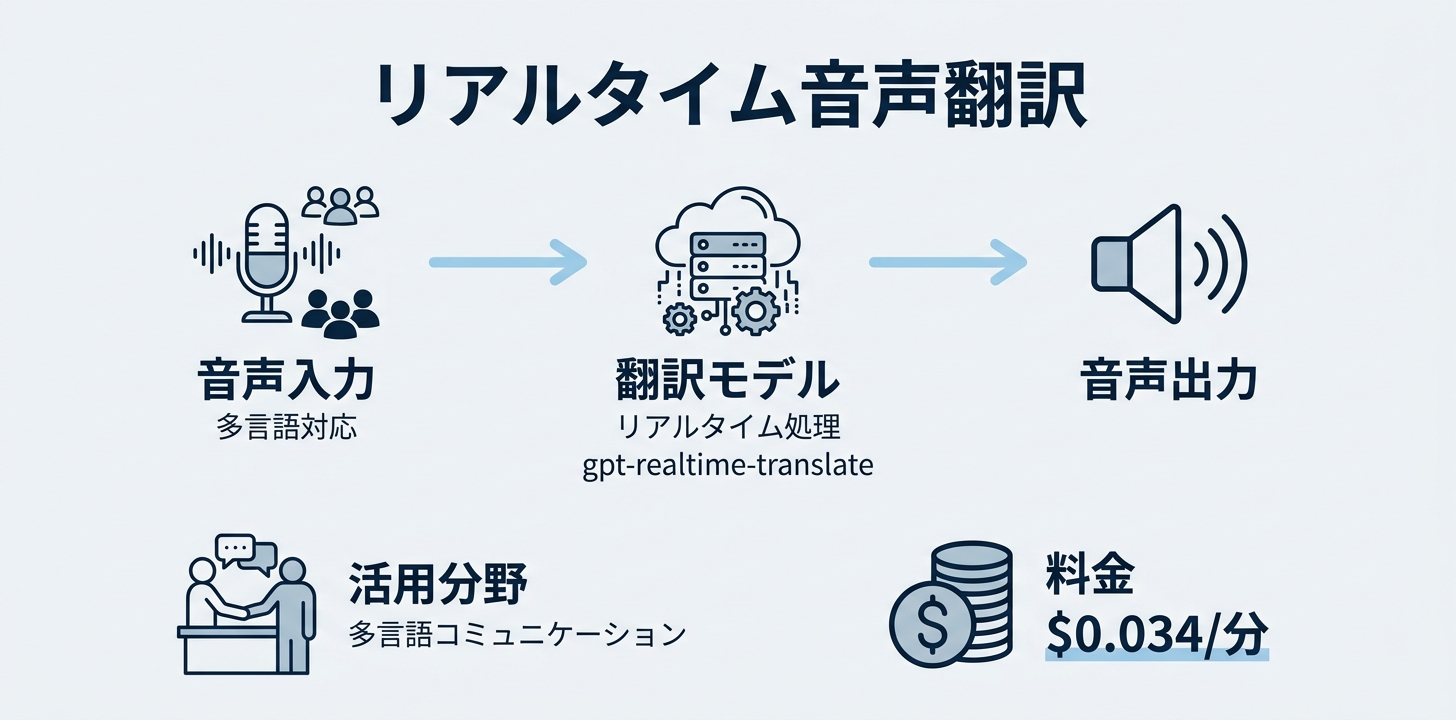
多言語の音声入力をリアルタイムに翻訳して音声出力する専用モデルです。料金は 1分あたり$0.034(音声出力分のみ課金)というシンプルな体系になっています。
コールセンターの多言語対応、外国人労働者とのコミュニケーション、インバウンド観光業など、リアルタイム翻訳が必要な業務に特化しています。
以下は、リアルタイム翻訳モデルの実際のデモ動画です。音声がリアルタイムで翻訳されている様子が確認できます。
gpt-realtime-whisper — ストリーミング文字起こし
音声のリアルタイム文字起こしに特化したモデルです。バッチ処理型のWhisperと異なり、音声が入力されるそばから逐次テキスト化していきます。
モデル一覧と位置づけ
| モデル | 位置づけ | 主な用途 |
|---|---|---|
| gpt-realtime-2 | 最新フラッグシップ | 汎用音声エージェント |
| gpt-realtime-1.5 | 前世代フラッグシップ | カスタマーサポート |
| gpt-realtime | GA版初代モデル | 安定運用重視 |
| gpt-realtime-mini | 軽量・低コスト版 | コスト重視の用途 |
| gpt-realtime-translate | 翻訳特化 | 多言語リアルタイム翻訳 |
| gpt-realtime-whisper | 文字起こし特化 | ストリーミング音声認識 |
料金体系|モデル別コスト比較
Realtime APIの料金は、テキストと音声で単価が異なります。以下はOpenAI公式の料金ページ(2026年5月時点)からの情報です。
gpt-realtime-2
| 項目 | 料金(1Mトークンあたり) |
|---|---|
| テキスト入力 | $4.00 |
| テキスト出力 | $24.00 |
| 音声入力 | $32.00 |
| 音声出力 | $64.00 |
| キャッシュ済み入力 | $0.40 |
| 画像入力 | $5.00 |
gpt-realtime-mini(低コスト版)
| 項目 | 料金(1Mトークンあたり) |
|---|---|
| テキスト入力 | $0.60 |
| テキスト出力 | $2.40 |
| 音声入力 | $10.00 |
| 音声出力 | $20.00 |
gpt-realtime-translate
$0.034/分(音声出力のみ課金)
コスト感の目安
gpt-realtime-2での音声通話は、音声入出力の比率やキャッシュ率によって変動しますが、目安として1分あたり数十セント(数十円)程度のコスト感です。プロンプトキャッシングを活用すると入力コストを大幅に削減できるため、繰り返し同じシステムプロンプトを使う音声エージェントでは特に効果的です。
miniモデルは音声入出力が約3分の1の単価で、大量処理やコスト重視のユースケースに向いています。
実際に試してみた|gpt-realtime-2で何ができるのか
ここからは、実際にgpt-realtime-2をPythonで動かして試した結果を紹介します。接続方法はWebSocket経由で、APIキーがあればすぐに試せる構成です。
テキスト対話:質問を送ると即座にテキストで返ってくる
まず、最もシンプルな使い方として、テキストメッセージを送ってテキストで回答を受け取ってみました。
与えたプロンプト(システム指示):
あなたは親切な日本語アシスタントです。簡潔に回答してください。
送ったメッセージ:
OpenAIのRealtime APIを一言で説明してください。
返ってきた回答:
Function Calling:AIが自分で外部データを取りに行く
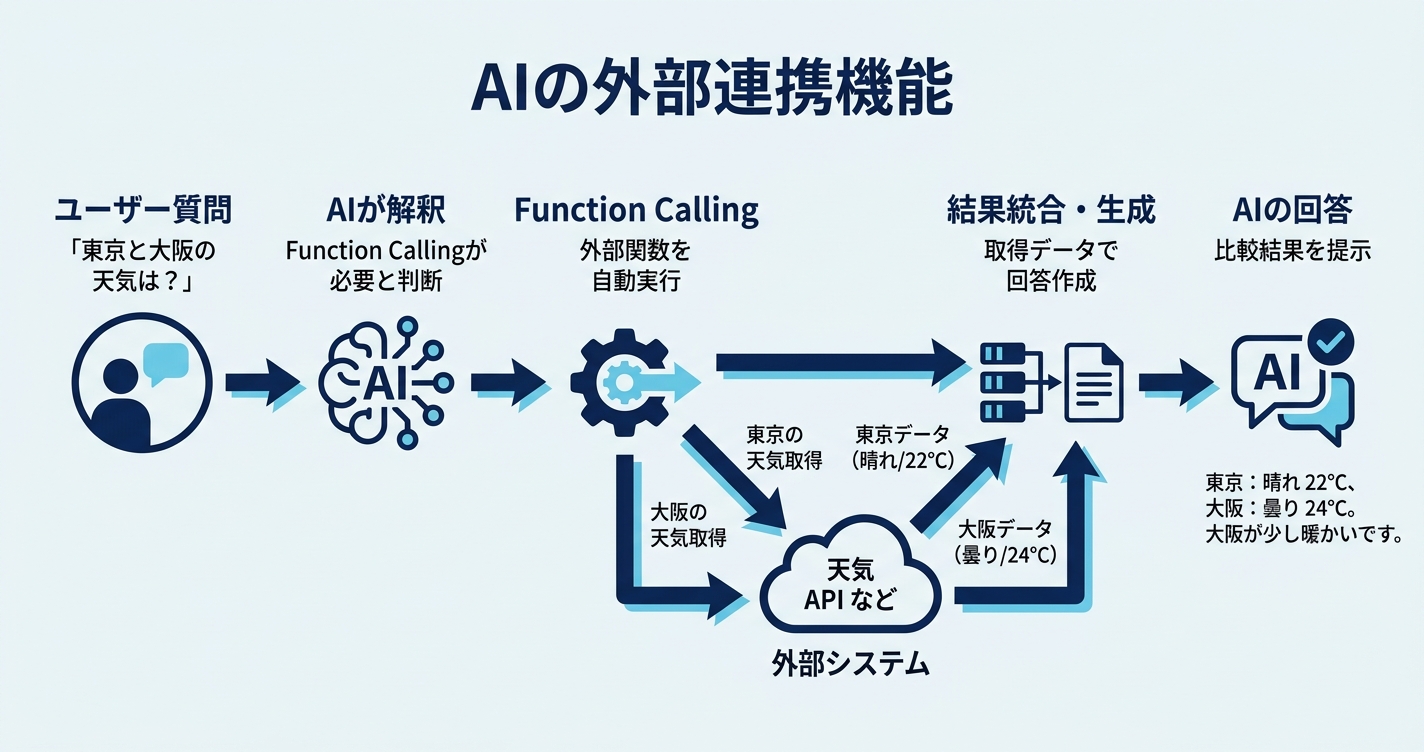
Realtime APIの強力な機能の一つが Function Calling です。「こういうデータが取れる関数がある」とAIに伝えておくと、会話の流れに応じてAIが自動的にその関数を呼び出し、結果を踏まえて回答を生成します。
ここでは、天気情報を返す関数を用意し、「東京と大阪の天気を比較して」と依頼してみました。
与えたプロンプト(システム指示):
日本語で簡潔に回答してください。天気を聞かれたら必ず get_current_weather 関数を呼び出してください。
送ったメッセージ:
東京と大阪の天気を比較して、簡潔に教えてください。
AIの動き:
- まず
get_current_weather({"city": "東京"})を自動で呼び出し → 結果: 晴れ / 22℃ / 湿度45% - 続けて
get_current_weather({"city": "大阪"})を呼び出し → 結果: 曇り / 24℃ / 湿度55% - 両方の結果を統合して回答を生成
返ってきた回答:
音声生成:テキストから自然な日本語音声を作る
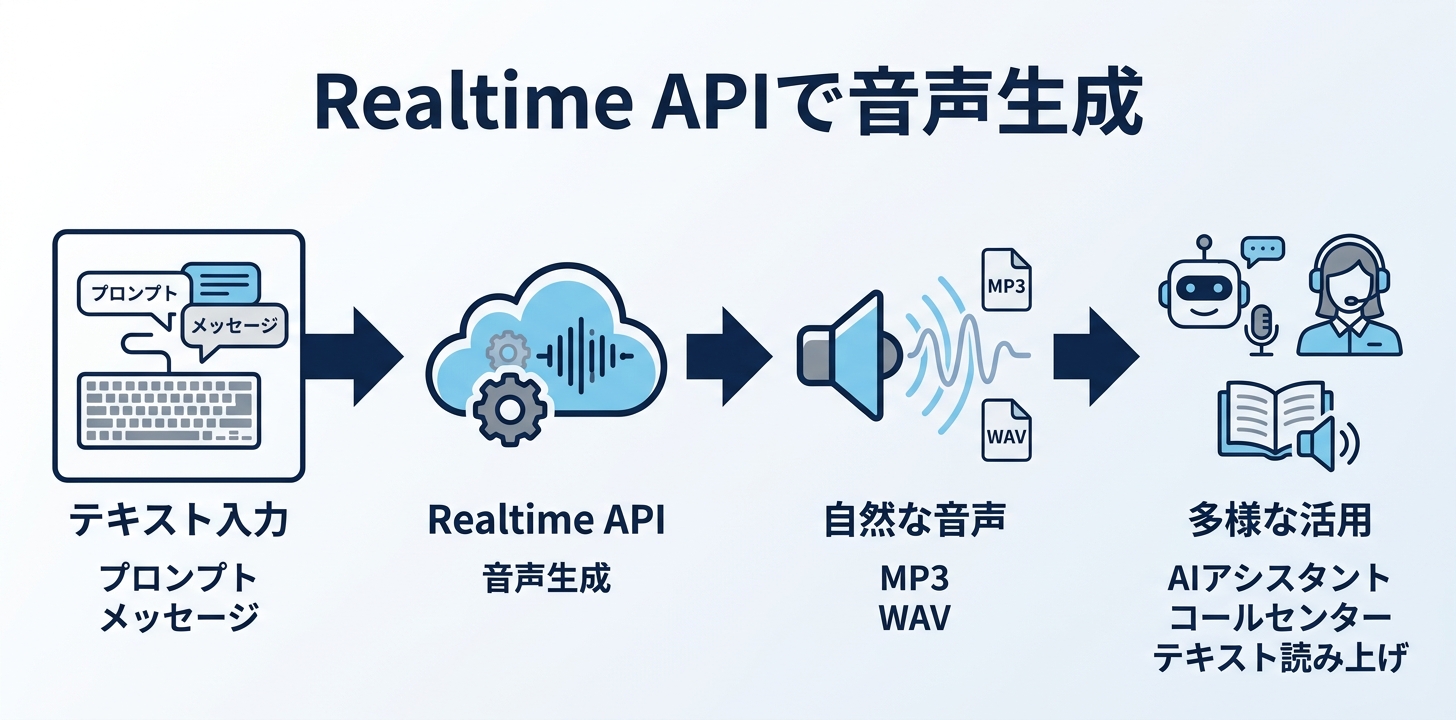
Realtime APIは、リアルタイム対話だけでなく テキストを送って音声で応答を受け取り、アプリ側でファイルとして保存する 使い方もできます。出力モードを「音声」に切り替えてテキストを送ると、音声データがストリーミングで返ってくるので、アプリ側でMP3やWAVとして保存できます。
実際に3つのパターンで音声を生成してみました。
サンプル1: 「Realtime APIについて説明して」(31秒)
与えたプロンプト:
あなたはAI技術に詳しい日本語のアシスタントです。わかりやすく、自然な話し方で回答してください。
送ったメッセージ:
OpenAIのRealtime APIについて、30秒程度で簡潔に説明してください。
返ってきた音声:
サンプル2: コールセンター応対(15秒)
与えたプロンプト:
あなたはコールセンターのAIオペレーターです。丁寧で落ち着いた口調で、日本語で対応してください。
送ったメッセージ:
お客様から「料金プランを変更したい」と電話がかかってきました。丁寧に対応してください。
返ってきた音声:
サンプル3: 指定テキストの読み上げ(14秒)
与えたプロンプト:
指示されたテキストを正確に読み上げてください。自然な日本語の発音で、落ち着いたトーンで話してください。
送ったメッセージ:
以下のテキストをそのまま読み上げてください。「Realtime APIを使えば、テキストから自然な音声をリアルタイムに生成できます。カスタマーサポート、多言語翻訳、音声ナビゲーションなど、さまざまなビジネスシーンで活用できます。」
返ってきた音声:
日本語の発音もかなり自然で、サンプル2のコールセンター応対などは実務に使えそうな品質です。OpenAIには専用のTTS API(/v1/audio/speech)も別にありますが、Realtime APIの利点は 対話の文脈を踏まえた音声生成ができる 点です。「さっきの説明をもう少し詳しく」といった追加指示にも、同じセッション内で対応できます。
コールセンターでの活用|具体的なシーンと実装イメージ
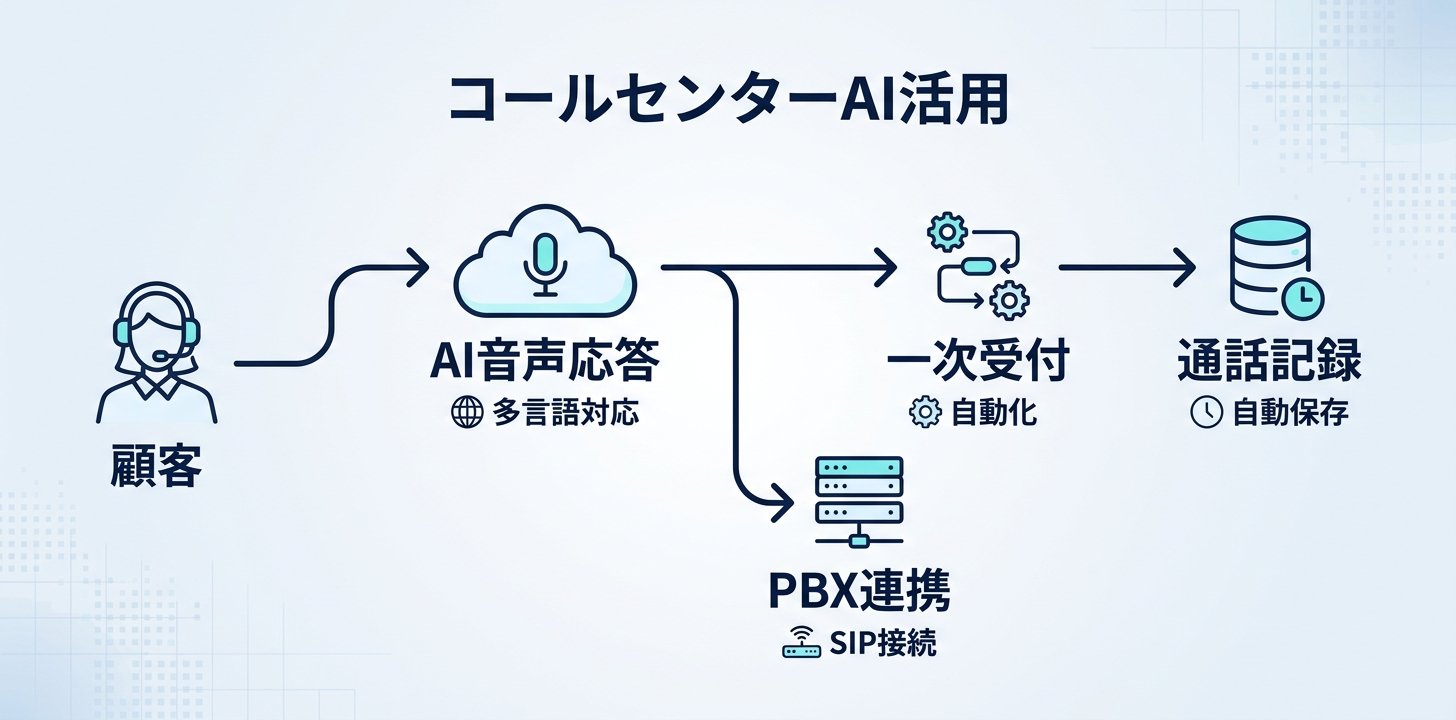
Realtime APIの活用先として、最も導入効果が見えやすいのがコールセンター業務です。ここでは、日本企業での具体的な適用シーンを紹介します。
一次受付の自動化
電話がかかってきたら、まずAIが音声で応答します。SIP接続を使えば既存のPBXシステムにそのまま接続できるので、電話番号を変えずに導入できます。
対応フローの例:
- 顧客が電話をかける
- AIが音声で「お電話ありがとうございます。ご用件をお聞かせください」と応答
- 顧客が「料金プランを変更したい」と発話
- AIがFunction Callingで社内の顧客管理システムを照会
- 「現在のプランはAプランですね。Bプランへの変更でよろしいですか?」と確認
- 単純な変更はAIが完結 / 複雑な案件はオペレーターに転送
よくある問い合わせの即時回答
「営業時間は?」「返品の手続きは?」「残高を確認したい」といった定型的な問い合わせに、24時間・待ち時間なしで対応できます。Function Callingと組み合わせれば、顧客情報をリアルタイムに参照しながらの回答も可能です。
多言語対応
gpt-realtime-translateを使えば、日本語で対応できないオペレーターの代わりに、AIが多言語の音声入力をリアルタイムに翻訳して対応できます。外国人居住者からの問い合わせが増えている自治体窓口や、インバウンド需要の多い宿泊・観光業などで効果が見込めます。
通話内容の自動記録
gpt-realtime-whisperを併用すれば、通話内容をリアルタイムに文字起こしして記録できます。オペレーターが対応中にメモを取る必要がなくなり、通話後のログ入力作業も削減できます。
導入時の注意点
| 検討項目 | ポイント |
|---|---|
| コスト試算 | 1通話あたりのトークン消費量を事前に見積もる。1分あたり数十円程度が目安 |
| フォールバック | AIで対応しきれない場合のオペレーター転送フローは必須 |
| 個人情報の扱い | APIでPHI(保護対象医療情報)を扱うにはBAAが前提。ただし一部APIサービスは対象外のため、個別に確認が必要 |
| 音声品質 | 電話回線経由の音質劣化を考慮し、ノイズリダクション設定を検討 |
| セッション時間 | 長時間セッションでは接続管理が必要。公式ドキュメントで上限を確認 |
ビジネスでの活用シーン
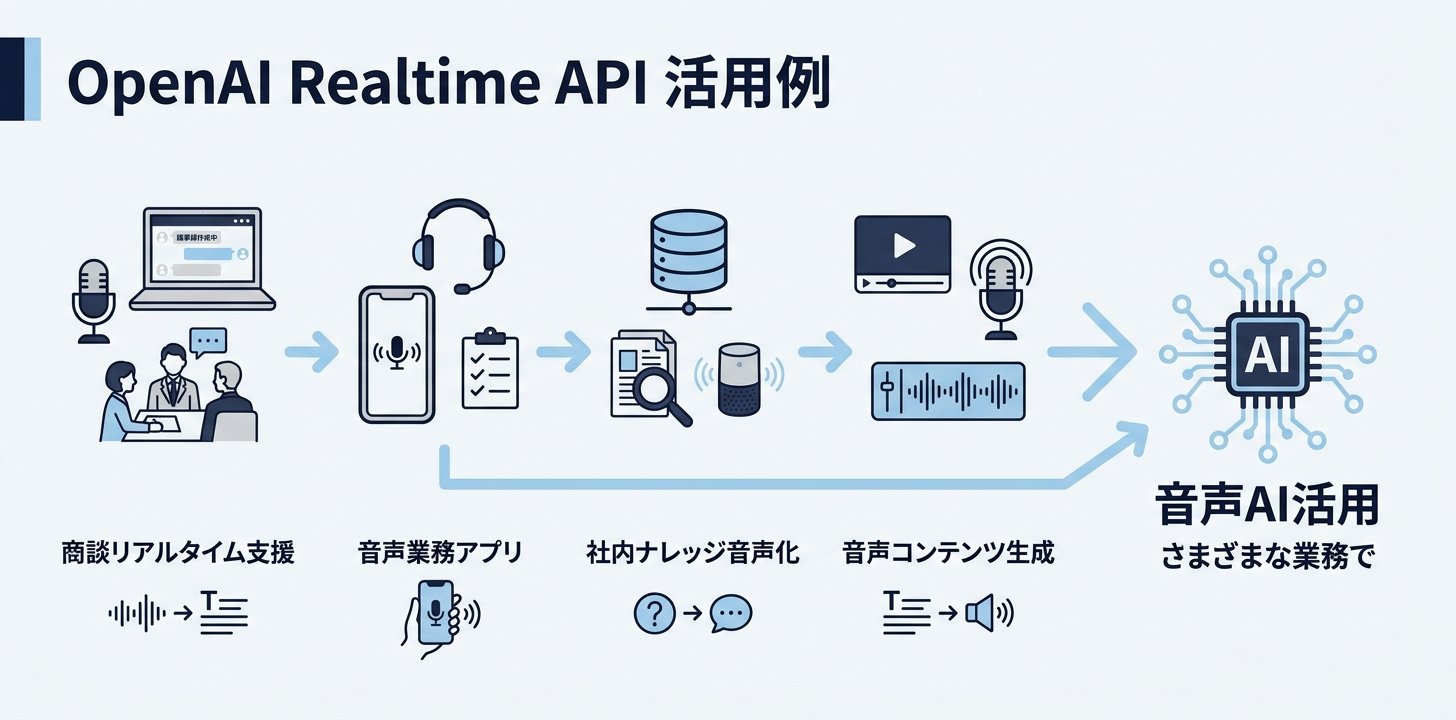
コールセンター以外にも、Realtime APIが効果を発揮するビジネスシーンを紹介します。
営業・商談のリアルタイム支援
営業担当者が商談中にイヤホン越しでAIアシスタントと会話し、製品仕様や見積もりをその場で確認する使い方です。Function Callingでバックエンドシステムと連携すれば、「在庫あと何個?」「この構成の見積もりは?」といった質問にリアルタイムで回答できます。
音声ベースの業務アプリ
現場作業中に手が塞がっている状況——製造ラインの点検、倉庫での棚卸し、医療現場でのカルテ記録など——で、音声だけでAIとやり取りしてデータ入力や情報照会を行うアプリを構築できます。
社内ナレッジの音声アシスタント化
社内マニュアルやFAQデータベースをFunction Callingで接続し、従業員が音声で質問すると関連情報を音声で回答する社内アシスタントの構築が可能です。新人教育や多拠点間のナレッジ共有に活用できます。
音声コンテンツの自動生成
Demo 3で紹介したTTS的な使い方を応用すれば、ブログ記事の音声版、eラーニング教材のナレーション、社内通知の音声化など、テキストコンテンツの音声化を自動で行えます。
導入前に知っておくべき制限事項
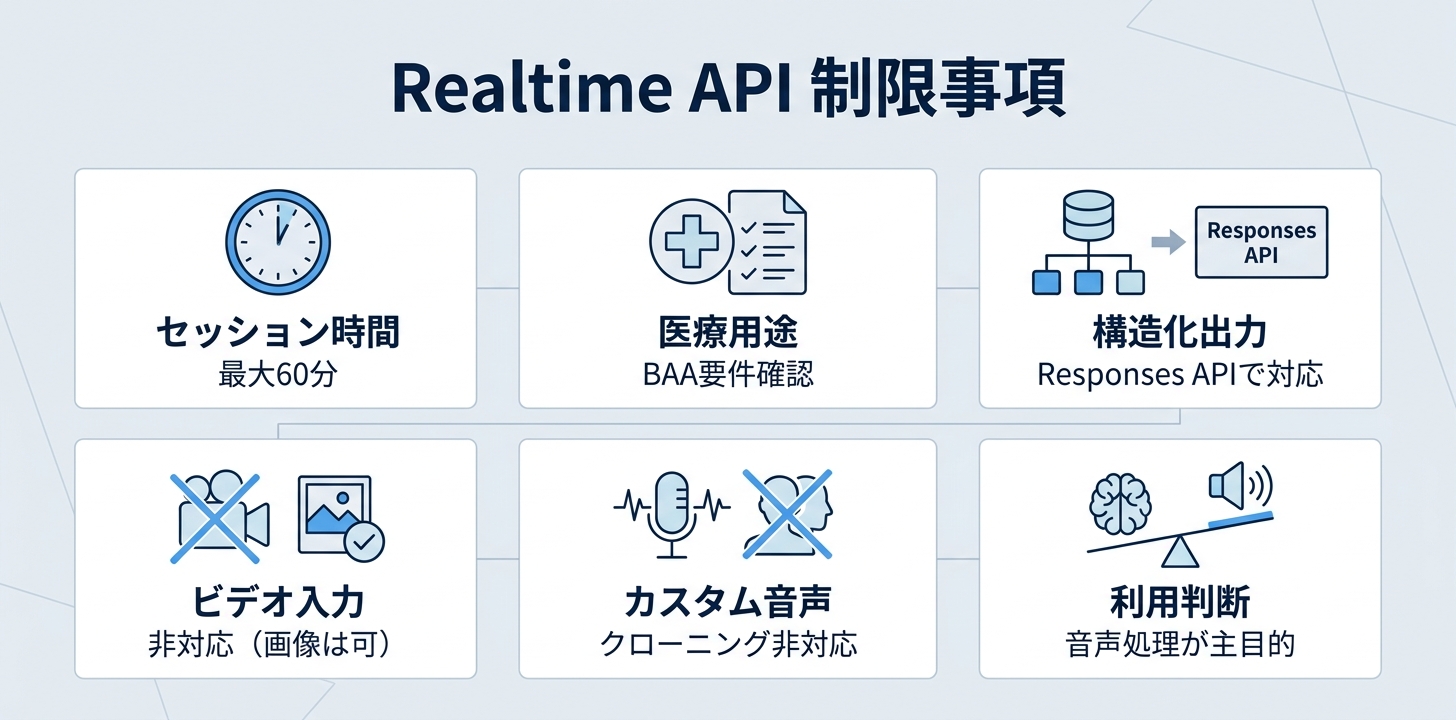
Realtime APIには、導入前に把握しておくべき制限がいくつかあります。
| 制限事項 | 詳細 |
|---|---|
| セッション時間 | 長時間セッションでは接続管理が必要 |
| 医療用途 | BAA締結が前提。対象外例外あり(個別確認が必要) |
| 構造化出力 | Responses APIで対応(Realtime APIでは未対応) |
| ビデオ入力 | 非対応(画像は対応) |
| カスタム音声 | 音声クローニングは非対応 |
医療用途については、APIでPHI(保護対象医療情報)を扱うにはBAA(Business Associate Agreement)の締結が前提です。ただし、多くのAPIサービスが対象である一方、一部例外もあるため、OpenAIのBAA対象サービス一覧で個別に確認してください。
また、構造化出力(Structured Outputs)については、現時点ではRealtime APIよりResponses APIの方が向いています。構造化されたデータ取得が必要な場合は、Function Callingで代替するか、Responses APIとの併用を検討してください。
Realtime APIは音声処理が主目的のAPIです。テキストだけの処理であればResponses APIのほうがシンプルかつ低コストなので、「音声が絡むかどうか」がRealtime APIを選ぶ判断基準になります。
まとめ
OpenAI Realtime APIは、2026年5月7日のアップデートで「gpt-realtime-2」「gpt-realtime-translate」「gpt-realtime-whisper」の3モデルが追加され、本格的な音声AI基盤として整ってきました。
この記事のポイントを整理します。
- gpt-realtime-2 は高い推論性能を備えた最新モデル。Function Callingも実用レベルで動作する
- 音声ファイル生成(TTS的な使い方)にも対応しており、対話の文脈を踏まえた音声を生成できる
- gpt-realtime-translate は多言語のリアルタイム翻訳を1分$0.034で提供
- コールセンターの一次受付自動化、多言語翻訳、営業支援など、「リアルタイムの音声AI」が必要なビジネスシーンで導入効果が高い
「自社の業務にリアルタイム音声AIを組み込みたいが、どこから始めればいいかわからない」という方は、まずはOpenAI公式のRealtime APIドキュメントでWebSocket接続の基本を押さえるところから始めてみてください。本記事で紹介したように、テキストモードでの動作確認から入ると、仕組みの全体像をつかみやすいです。

この記事の著者 / 編集者

