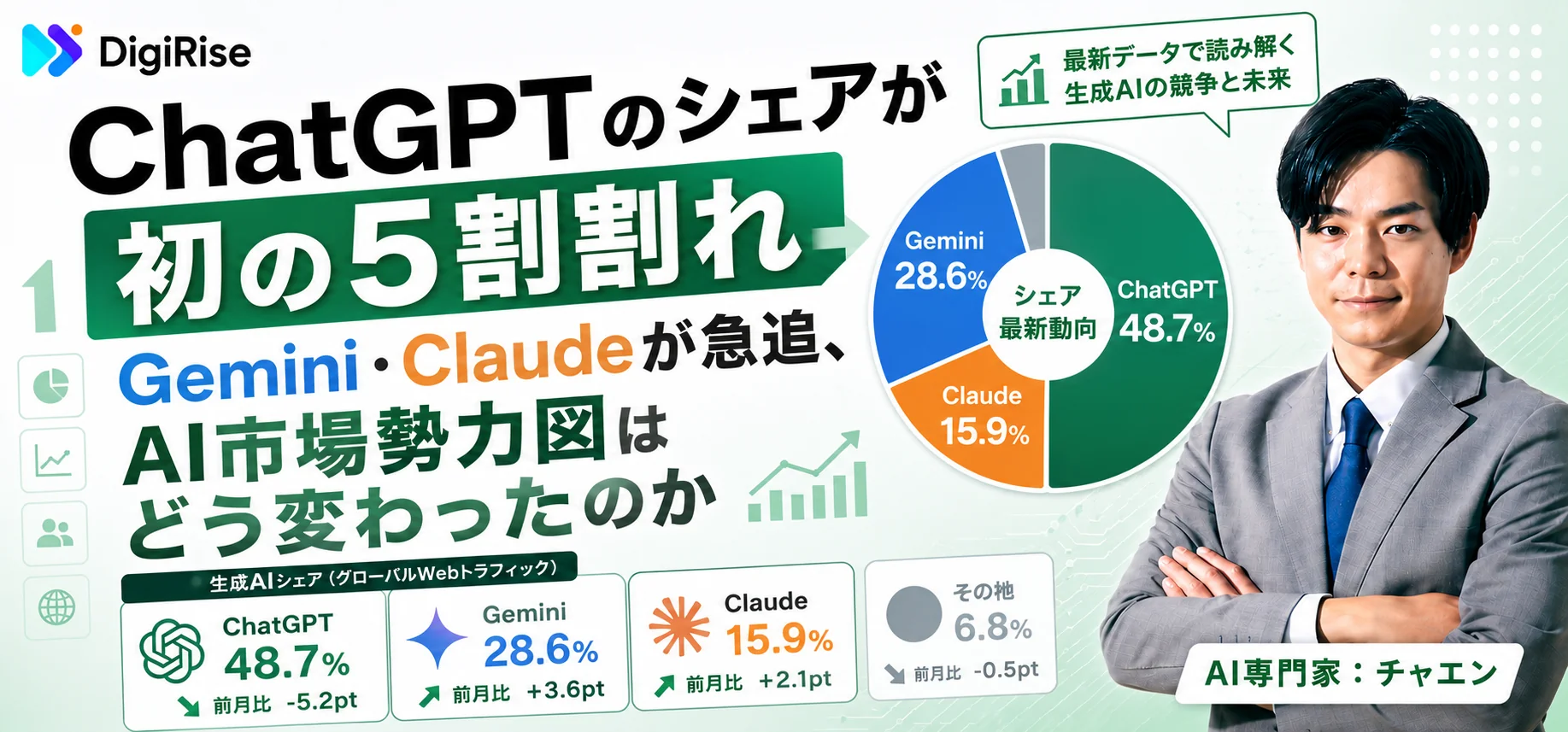
近年、ChatGPTなどの生成AIの登場・普及が世界的に話題となっているように、AIは人々の暮らしや仕事をより便利に・効率的にするツールとして大きな注目を集めています。
企業のさまざまな部門で、業務効率化や顧客体験の向上、意思決定の精度向上など、多くの用途でAIが活用されています。
「自社でもAIを活用したいけれど、何から始めればいいのかわからない」「具体的にどんな効果があるのか知りたい」そんなお悩みはありませんか?
デジライズでは、AI活用を検討している企業の皆様に向けて、AI活用事例や導入のポイントをわかりやすくご紹介します。
ご興味のある方は以下のリンクから、お問い合わせいただけます。
2025年7月24日、Google DeepMindが学術誌『Nature』に発表した論文が、歴史学・考古学界に衝撃を与えています。古代ラテン語碑文の文脈化を専門とする初のAIモデル「Aeneas」の登場により、風化や破損で読めなくなった古代ローマの碑文を高精度で復元し、その年代や起源地まで特定することが可能になりました。
この技術革新は、単なる文字認識を超えて、古代世界の社会、文化、政治を理解する上で計り知れない価値を持つ歴史的文書を、現代に甦らせることを可能にします。

目次
革命的AI「Aeneas」の誕生:古代文字解読の新時代
古代ローマ世界の膨大な文字遺産
古代ローマ帝国は、まさに「文字の世界」でした。皇帝の記念碑から日常用品まで、あらゆるものに文字が刻まれ、政治的落書き、愛の詩、墓碑銘、商取引記録、誕生日の招待状、魔術の呪文まで、多様な碑文が現代まで残されています。Nature論文によると、毎年約1,500の新しいラテン語碑文が発見されており、500万平方キロメートルに及ぶ帝国領土から2,000年以上にわたる貴重な文化・言語情報を保存しています。
Aeneasが解決する根本的課題
しかし、これらの碑文の多くは以下の問題に直面しています:
- 物理的損傷:風化、破損、意図的な破壊による文字の消失
- 文脈情報の欠如:高い移動性、明示的な日付の不在
- 専門知識の必要性:ラテン語特有の略語の頻繁な使用
従来、歴史学者はこれらの問題を解決するために、類似碑文(parallels)を手作業で特定する必要がありました。これは単語、句、定型表現、より広範な社会的・言語的・文化的類似点を共有する碑文を見つける作業で、極めて時間がかかり、高度な専門知識を要求されました。

ギリシャ・ローマ神話の英雄にちなんだ命名
Aeneasという名称は、ギリシャ・ローマ神話の放浪の英雄アイネイアース(エネアス)に由来します。トロイアから地中海を渡り、未来のローマ建国の地を求めて旅をした英雄のように、このAIモデルも碑文間の類似点を探し求めて、過去と現代を結ぶことを目指しています。
従来技術を凌駕する圧倒的性能:Nature論文が示す驚異のベンチマーク
前身モデル「Ithaca」からの飛躍的進歩
AeneasはGoogle DeepMindが2022年に発表した古代ギリシャ語碑文解読AI「Ithaca」の後継モデルです。しかし、その性能向上は革命的といえるレベルに達しています。
文字復元精度の劇的向上
文字復元タスクにおける性能比較:
| 条件 | Aeneas | Ithaca | 改善率 |
|---|---|---|---|
| 10文字以下の復元(Top-20精度) | 73% | 62% | +18% |
| 未知長さの復元(Top-20精度) | 58% | – | 新機能 |
| 文字誤り率(CER) | 40.5% | – | 最先端 |
地理的属性予測の精度:
- 62の古代ローマ属州から正確な起源地を特定:72%の精度
- マルチモーダル入力(テキスト+画像)により、テキスト単体を大幅に上回る性能
年代測定の驚異的精度:
- 歴史学者による年代範囲から平均13年以内で正確な年代を予測
- 中央値では誤差0年という驚異的な精度を達成
統計的有意性の確認
Nature論文によると、AeneasとIthaca間のすべての性能比較において統計的有意性が確認されています(順列検定:文字復元 P < 0.0001、地理的属性 P < 0.0001、年代測定 P < 0.0005)。
マルチモーダルAIの力:テキストと画像を統合した革新的アプローチ
画期的なマルチモーダル・アーキテクチャ
Aeneasの最も革新的な特徴の一つは、古代碑文研究で初めてマルチモーダル入力を処理できることです。従来のAI手法がテキスト中心だったのに対し、Aeneasはテキストの転写と碑文の画像の両方を同時に分析します。
技術仕様の詳細
コアアーキテクチャ:
- T5トランスフォーマーベースの「胴体(torso)」:384次元の埋め込み、16層、8つの注意ヘッド
- 専門化された「頭(heads)」:4つのタスク別ニューラルネットワーク
- 視覚処理:ResNet-8ベースの浅い視覚ニューラルネットワーク
- 最大入力長:768文字、224×224ピクセルのグレースケール画像
特殊記号システム:
- 「-」記号:文字数が既知の欠損部分
- 「#」記号:文字数不明の欠損部分(業界初の対応)
ラテン語エピグラフィーデータセット(LED)
AeneasのトレーニングのためにGoogle DeepMindが構築したLEDは、176,861のラテン語碑文(総計1,600万文字)を含む史上最大の機械学習用ラテン語碑文データセットです。
データソース:
- Epigraphic Database Roma (EDR)
- Epigraphic Database Heidelberg (EDH)
- Epigraphik-Datenbank Clauss-Slaby ETL (EDCS_ETL)
地理的・時代的範囲:
- 時代:紀元前7世紀から紀元後8世紀
- 地域:ブリタニア(現イギリス)からメソポタミア(現イラク)まで

歴史学者との協働評価:人間とAIの理想的なコラボレーション
史上最大規模の「歴史学者×AI」協働研究
Google DeepMindは、23人の碑文学専門家(修士学生から教授まで)を対象とした大規模な協働評価を実施しました。これは古代史分野における「人間とAI」の協働研究としては過去最大規模です。
3段階評価プロセス
段階1:歴史学者単独の性能
- 5つの碑文を個別に分析
- 復元、年代測定、地理的特定を実施
- ベースライン性能の確立
段階2:Aeneasの類似碑文情報を活用
- Aeneasが提供する10の類似碑文を参考に作業
- 文脈情報の影響を測定
段階3:Aeneasの予測結果も併用
- Aeneasの復元・属性予測も利用
- 最終的な協働性能を評価
劇的な性能向上の実証
文字復元タスク:
| 条件 | 文字誤り率(CER) | 改善率 |
|---|---|---|
| 歴史学者単独 | 39% | – |
| +Aeneas類似碑文 | 33% | 15%改善 |
| +Aeneas予測 | 21% | 46%改善 |
地理的属性予測:
| 条件 | Top-1精度 | Top-3精度 | 改善率 |
|---|---|---|---|
| 歴史学者単独 | 27% | 42% | – |
| +Aeneas類似碑文 | 35% | 55% | 35%改善 |
| +Aeneas予測 | 68% | – | 152%改善 |
年代測定:
- 歴史学者単独:平均31.3年の誤差
- +Aeneas類似碑文:21.3年の誤差(32%改善)
- +Aeneas予測:14.1年の誤差(55%改善)
歴史学者からの絶賛コメント
「Aeneasが提供した類似碑文により、碑文に対する認識が完全に変わった。復元と年代特定の両方で決定的な違いをもたらす詳細に気づかせてくれた。」
—評価参加歴史学者(匿名)
「Aeneasの助けがあれば、15分で見つけることができる文献を、従来なら数日かけて探す必要があった。今では文献検索ではなく、研究課題の構築と執筆に時間を使える。」
—評価参加歴史学者(匿名)

実世界での衝撃的成果:アウグストゥス帝『業績録』の謎を解明
「ラテン語碑文の女王」への挑戦
Aeneasの真の実力を証明するため、研究チームは古代世界で最も重要な碑文の一つである『アウグストゥス帝業績録(Res Gestae Divi Augusti, RGDA)』の分析に挑戦しました。
RGDAの重要性:
- 初代ローマ皇帝アウグストゥスの自伝的記録
- 「ラテン語碑文の女王」と称される歴史的文書
- ローマ帝国イデオロギー理解の基本資料
- トルコ・アンカラの神殿壁面に刻まれた最も完全な写本
長年の学術論争を数値化
歴史学者の間で長年議論されてきたRGDAの成立年代について、Aeneasは画期的な分析結果を提示しました。
Aeneas の年代分析結果:
- 二峰性分布を検出:紀元前10-1年頃の小さなピークと、紀元後10-20年の大きく確信度の高いピーク
- 従来の学説を定量的に表現:対立する二つの仮説を確率分布として可視化

高度な言語分析能力の実証
Aeneasの分析は、文書中の執政官年代に惑わされることなく、以下の微細な言語的特徴に基づいて判断を行いました:
注意機構が検出した時代指標:
- 古式ラテン語正書法:「aheneis」から「aeneis」への1世紀の綴り変化
- 歴史的制度:「princeps iuventutis」(青年指導者)の称号(紀元前5年初出)
- 記念建造物:アウグストゥス平和祭壇(紀元前13年建設開始)
- 非ローマ人名:特定の時代文脈を持つ外国人名の言及
類似碑文検索の驚異的精度
AeneasがRGDAに対して提示した上位5つの類似碑文は、すべてローマで作成された文書でした。発見地点は多様であったにも関わらず、作成地の特定に成功しています。
特に注目すべき類似碑文:
- ウァレリウス・アウレリウス法(19年):ゲルマニクス顕彰のための元老院布告
- 帝国イデオロギー関連文書:アウグストゥス家族顕彰の言語的特徴を共有
これらの結果は、Aeneasがローマ帝国イデオロギーの地理的拡散という重要な歴史的現象を、AIによって客観的に捉えることができることを示しています。
技術的革新の詳細:176,000の碑文から学習した最先端アーキテクチャ
革新的な文脈化メカニズム
Aeneasの最大の技術的革新は、「文脈化(contextualization)」メカニズムにあります。これは従来の単純な文字列マッチングを超えて、歴史的・言語的パターンを捉えた「歴史的に豊かな埋め込み(historically rich embeddings)」を生成する技術です。
埋め込みベクトルの特徴:
- 4つのエピグラフィ・タスクから統合された表現
- 意味と文脈の両方に基づく比較が可能
- コサイン類似度による関連性ランキング
訓練プロセスの詳細
計算資源:
- Google Cloud TPU v5e 64チップで1週間の訓練
- バッチサイズ1,024のテキスト・画像ペア
- LAMB オプティマイザー、学習率 3×10^-3
データ拡張技術:
- 最大75%のテキストマスキング
- テキストクリッピング、単語削除
- 明度・コントラスト調整等の画像拡張
- 10%ドロップアウト、ラベル平滑化
多タスク学習の重み調整:
L = 3L_restoration + L_unknown + 2L_region + 1.25L_date顕著性マップによる解釈可能性
Aeneasは予測の根拠を顕著性マップ(saliency maps)として可視化します。これにより、AIが注目した文字や画像の特徴を歴史学者が理解することができます。
実際の顕著性マップが示した注目ポイント:
- 執政官年代記録式
- 神々の呼称(Deae Aufaniae)
- 地域特有の言語的マーカー
考古学・歴史学界への波及効果
パラダイム転換の予兆
Aeneasの登場は、古代史研究における以下の根本的変化を示唆しています:
研究手法の革命:
- 手作業による類似碑文検索から→AI支援による大規模並行検索へ
- 推測に基づく復元から→確率論的・定量的な復元へ
- 地域専門化から→帝国全域を俯瞰する横断的研究へ
研究効率の劇的向上:
- 数日かかる文献調査→数分での類似文書特定
- 主観的な年代推定→平均13年以内の客観的年代測定
- 限定的な地域知識→62属州全体を網羅する地理的識別
教育分野への応用
Google DeepMindは新しい教育シラバスも開発し、以下の枠組みに準拠しています:
- EU デジタル能力枠組み(DigComp 2.2)
- UNESCO AI能力枠組み
- OECD AI リテラシー枠組み
オープンソース化による学術界への貢献
公開リソース:
- Aeneas インタラクティブ版:研究者・学生・教育者向け無料アクセス
- コードとデータセット:オープンソース公開
- Nature論文:査読済み学術研究として公開
他の古代言語への拡張可能性
Nature論文によると、Aeneasのアーキテクチャは以下への適応が可能です:
- 古代ギリシャ語(既にIthacaをアップグレード済み)
- パピルス文書
- 古代硬貨銘文
- 写本
- その他の古代言語・文字体系

今後の展望:古代世界研究の未来
短期的発展(2025-2027年)
技術的改良:
- より多くの古代言語への対応拡大
- 画像解析精度の向上(現在5%の画像データを拡充)
- より長いテキストシーケンスへの対応
学術的応用:
- 世界各地の考古学博物館での実用化
- 既存の碑文データベースとの統合
- リアルタイム発掘現場での活用
中長期的影響(2028-2035年)
研究パラダイムの変革:
- デジタル考古学の本格的確立
- 計算史学(Computational History)の新分野創出
- AI支援型文献学の標準化
新たな歴史発見の可能性:
- 従来読解不可能とされた碑文群の大量解読
- 帝国全域にわたる言語変化・文化伝播の定量分析
- 失われた歴史的文書の系統的復元
技術的課題と限界
現在の制約:
- データセット規模の限界(1,600万文字)
- 碑文生存バイアス(保存状態の良い資料に偏重)
- 画像データの不足(全体の5%のみ)
将来の技術発展方向:
- より大規模なマルチモーダル・データセットの構築
- 量子コンピューティングとの統合
- リアルタイム3D碑文解析技術
人文学とAIの融合モデル
Aeneasは、人文学とAIの理想的な協働モデルを示しています:
相互補完的関係:
- AI:大規模データ処理、客観的パターン認識、高速並列検索
- 人間専門家:文脈的解釈、批判的思考、歴史的判断
新しい研究者像:
- AI支援型歴史学者:技術ツールを駆使しつつ人文学的洞察を維持
- 計算人文学者:統計的手法と伝統的史学を統合
- デジタル考古学者:現場調査とAI解析を組み合わせ
まとめ:古代の声を現代に甦らせるAIの革命
Google DeepMindの「Aeneas」は、単なる技術的革新を超えて、人類の歴史理解そのものを変革する可能性を秘めています。風化により失われつつある古代ローマの膨大な文字遺産を、最先端のAI技術により現代に甦らせることで、私たちは2000年前の人々の生活、思想、文化をより深く理解できるようになります。
Aeneasの真の価値は以下の点にあります:
- 技術的卓越性:73%の復元精度、13年以内の年代特定、72%の地理的識別精度
- 学際的協働:歴史学者との理想的なコラボレーションモデルの実現
- 学術的開放性:オープンソース化による知識の民主化
- 拡張可能性:他の古代言語・文字体系への適応可能性
- 教育的価値:次世代研究者の育成に向けた新しい学習枠組み
Nature論文が実証したように、AeneasとIthacaの性能差は統計的に有意であり、古代文字解読分野における明確なブレイクスルーを達成しています。さらに重要なのは、このAIが人間の専門家を置き換えるのではなく、人間の能力を増強し、研究の地平を大幅に拡大することです。
歴史学者の一人が語ったように、「Aeneasの助けにより、文献探索に費やしていた数日間を、研究課題の構築と執筆に充てることができるようになった」—この言葉は、AIが人文学研究にもたらす本質的な価値転換を端的に表しています。
古代ローマの詩人オウィディウスは『変身物語』で「時は万物を変化させる」と書きました。21世紀の今、AIという新たな力により、時の経過で失われた古代の声が再び私たちに語りかけ始めています。Aeneasは、過去と現在を結ぶ架け橋として、人類の知的遺産を未来へと継承する重要な役割を担っているのです。
Aeneas を今すぐ体験して、古代世界の扉を開いてください。
この記事の著者 / 編集者