






2026年4月23日(日本時間4月24日朝)、GPT-5.5 と GPT-5.5 Pro が発表されました。一言でいうと、「最強チャットAI」から「最強クラスの実務AI」への転換点になるモデルです。
チャットの賢さだけを競う時代は終わって、ツールを使い、自分で検証しながら、タスク完了まで走り切る ——そんな実務向きの能力で、主要ベンチマークで競合AIを上回る実績を残しています。
この記事では、GPT-5.4からの進化、発表時点でベンチマーク上で競合モデルを上回った具体的な指標、Codex側の強化点、料金、そしてあなたの業務でどう使うべきかまで、一気通貫で整理します。

目次
GPT-5.5とは?位置づけとモデルの使い分け
OpenAIの公式発表によると、GPT-5.5は「エージェント型コーディング、PC操作、ナレッジワーク、科学研究」の4領域を主軸に据えた新世代フロンティアモデルです。
ここ数ヶ月のOpenAIのモデル展開を振り返ると、GPT-5.5の立ち位置が見えてきますよね。
- GPT-5.3 Instant:前世代の高速応答特化チャットモデル(現在の高速応答枠は後継のGPT-5.5 Instant)
- GPT-5.4:推論・コーディング・PC操作・ツール連携を統合したオールインワン型
- GPT-5.5(今回):GPT-5.4の統合構造を踏襲しつつ、「実務で最後までやり切る」力を強化
つまり、GPT-5.5は5.4の延長線ではなく、「チャット応答の賢さを追うフェーズは終わった」というOpenAIのメッセージそのものに感じます。
GPT-5.5 と GPT-5.5 Pro の違い
今回は通常版とProの2ライン構成。違いはこちらです。
| 項目 | GPT-5.5 | GPT-5.5 Pro |
|---|---|---|
| 対象プラン | Plus / Pro / Business / Enterprise | Pro / Business / Enterprise のみ |
| 展開場所 | ChatGPT + Codex | ChatGPT のみ |
| 想定用途 | コーディング・調査・データ分析 | 法務・金融分析・科学研究など高難度タスク |
| 位置づけ | 標準の実務モデル | 反復的な「リサーチパートナー」として使う想定 |
Proは早期テスターから「反復的なリサーチパートナー」と評されていて、文書やプラグインと組み合わせた時に真価を発揮するとのこと。単発の回答の質というより、長時間かけて深掘りする系のタスクで差がつくイメージですね。
GPT-5.5が5.4から進化した5つのポイント
ここからが本題です。5.4から何が変わったのか、ベンチマーク数値が実務で何を意味するのかまで踏み込んで解説しますね。
① ターミナル上で複数工程タスクを自走
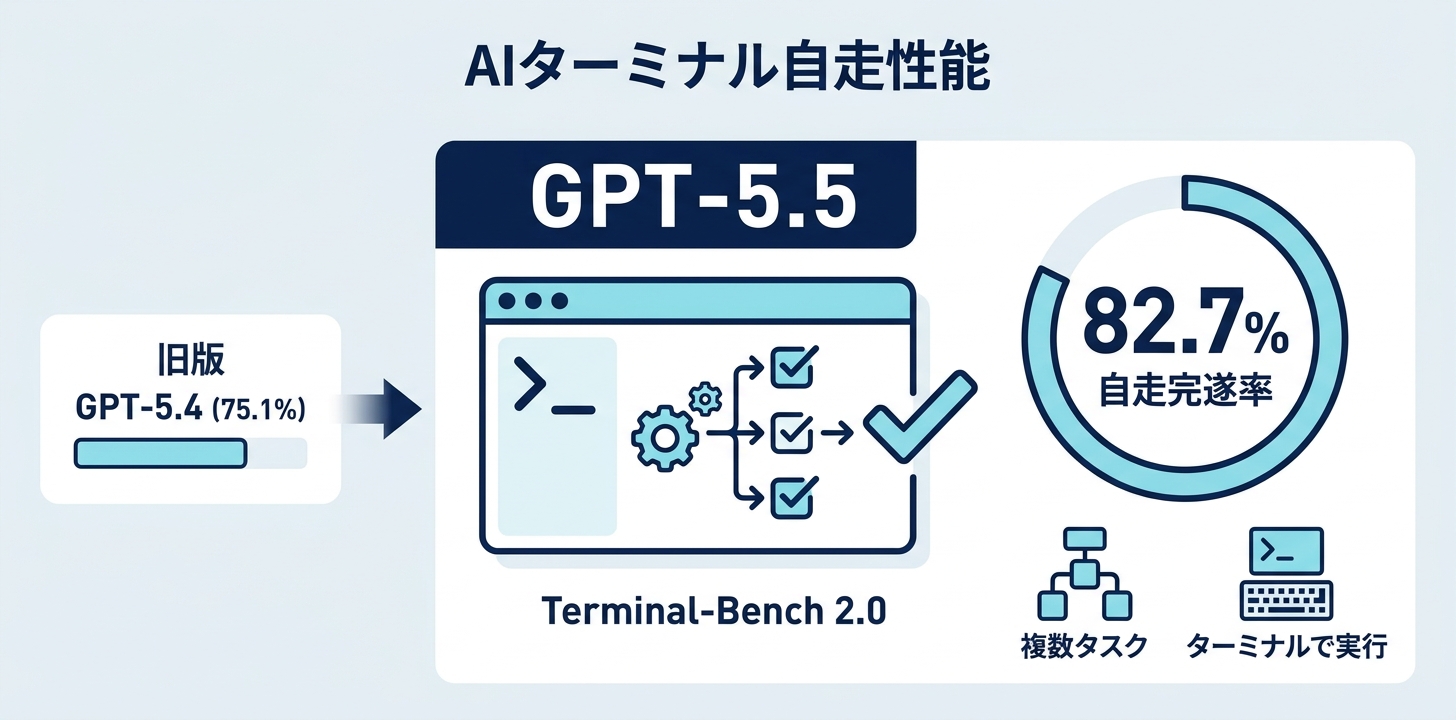
GPT-5.5は Terminal-Bench 2.0 で 82.7% を記録しました(GPT-5.4は75.1%で、+7.6ポイントの向上)。
Terminal-Benchは、ターミナル(コマンドライン)上で与えられた複雑なタスクを、AIがどこまで自走で完遂できるかを測るベンチマークです。82.7%という数字は、「ターミナルで指示した複数工程のタスクを最後まで完走できる確率」がそれだけ高まったことを意味します(もちろん実運用では承認フローや失敗時の切り戻しも必要なので、ベンチ結果と本番運用はイコールではありません)。
Codexのようなターミナルで動くAIエージェントで使うと、この差は体感としてかなり大きいです。
② PC操作とツール使用の底上げ
PC操作系・ツール使用系のベンチマークも軒並み強化されました。
- OSWorld-Verified:78.7%(実際のPC画面を見てクリック・入力・ナビゲーションする能力)
- Toolathlon:55.6%(多様なツールを組み合わせてタスクを完遂する能力)
ここがエージェント用途での実力を一番分かりやすく示す部分です。画面を見て → クリックして → 結果を確認して → 次の操作を判断する、という一連のループが安定してくると、業務自動化のシナリオが一気に広がりますよね。
③ 科学・研究領域への進出
学術・研究系の指標でも大きく伸びています。
- FrontierMath Tier4:35.4%(GPT-5.4は27.1%、+8.3ポイント)
- GeneBench:25.0%(GPT-5.4は19.0%、+6.0ポイント)
FrontierMath Tier4は数学研究の最難関層で、GeneBenchは遺伝学・定量生物学の多段階データ分析タスクです。研究者がアイデアを試行錯誤しながら証拠を集め、仮説を検証していく 「ループを粘り強く回す仕事」 が得意になってきた印象。
④ GPT-5.4と同レベルの応答速度
個人的にここが一番「実務向き」だと感じたポイントです。
GPT-5.5は、GPT-5.4と 同等の応答速度(1トークンあたりの生成時間が同水準) を維持したまま、ほぼすべての評価で性能向上を達成しています。賢くなったモデルは遅くなりがち、というこれまでの常識に反して、「賢い、速い、効率的」の三拍子が揃ったのは大きいです。
⑤ Codexでのトークン効率改善
Codex上でのトークン消費量も削減されています。同じタスクを完了するのに必要なトークン数が、GPT-5.4より少なくなっているそうです。
さらに面白いのが、GPT-5.5自身がCodexを使って自社の推論インフラを最適化し、トークン生成速度を20%以上向上させたというエピソード。AIがAIの基盤を改善する時代が、もう現実になってますね。
GPT-5.5が発表時点でClaude Opus 4.7を上回った5指標
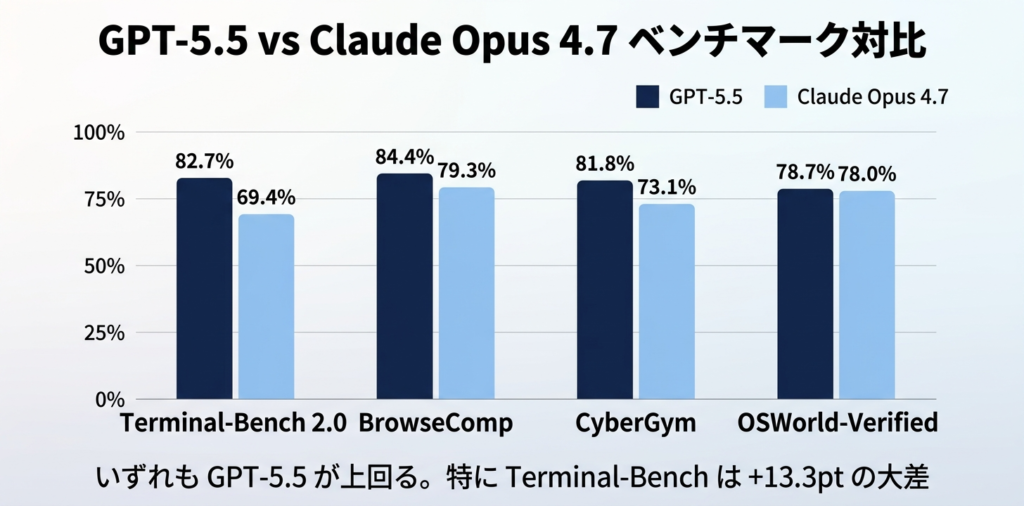
ここが今回の発表で最も話題になっているポイントです。チャエン目線で「Claude Opus 4.7を上回っていて実務で効く」と感じた指標を5つ、公式データから抜粋します。
| ベンチマーク | GPT-5.5 | 意味するところ |
|---|---|---|
| Terminal-Bench 2.0 | 82.7% | ターミナル上での自走力 |
| OSWorld-Verified | 78.7% | 実PC画面でのエージェント操作 |
| BrowseComp | 84.4% | Web調査・ブラウジングの精度 |
| CyberGym | 81.8% | サイバーセキュリティ系タスク |
| GDPval | 84.9% | 44職種の実務タスク対応力 |
GDPvalの 84.9% は、44の職種にわたる実務タスクにおいて、AIの成果物が業界プロフェッショナルの成果物と同等以上と評価された割合を示す指標です。GPT-5.4の時点でも83.0%で話題になりましたが、そこからさらに積み上げてきています(もちろんこれは評価用タスクでのスコアなので、そのまま「現場で任せきれる確率」ではない点は留意してください)。
もちろん「全ての指標でGPT-5.5がClaudeを上回る」わけではなく、推論重視・精密なコーディングでは当時のClaude Opus 4.7に分があるシーンもありました。ここは用途での使い分けが正解ですね。なお、この比較はいずれも発表当時(2026年4月)のもので、現在Anthropicの上位モデルは後継のClaude Opus 4.8に移行しています。最新の使い分けを検討する際は、各社の現行モデル同士で見比べるのがおすすめです。

Codex側の4大強化ポイント
GPT-5.5と同時に、Codex側にも大きなアップデートが入っています。モデル本体だけでなく、それを動かす実行環境もまるごと一段上に引き上げられたイメージです。
① Auto-reviewモード|承認の一部を自動化して長く走らせる
今回一番インパクトがあったのがこれです。Auto-reviewは、Codexがより少ない承認でより長く動ける新モード。
- Codex本体はテスト・ビルド・リファクタなどの作業を連続実行
- 別エージェントが「高リスクな手順」をコンテキスト込みで事前チェック
- 危ない手順の前だけユーザーにエスカレーション
これまでは「ファイルを変更しますか?」「このコマンドを実行しますか?」で頻繁に止まっていたCodexが、安全な手順はレビューエージェントが自動で承認し、長時間のオートメーションタスクを余計な停止なく走らせられるようになります(承認そのものを無くすのではなく、判断をエージェントに委ねる仕組みです)。深夜にコードベースを整備してもらったり、長時間かかる検証タスクを任せたり、使い道が一気に広がりますよね。
② ブラウザ操作の強化|WebアプリをCodexが直接触る
CodexがWebアプリを直接操作できるようになりました。
- ページ内をクリック・スクロール・入力
- テストフローを自動で実行
- スクリーンショットを取得して結果確認
- 見た内容に基づいて次の操作を判断
「手動で触らないと再現できないバグ」や「E2Eテストの自動化」が、専用ツール無しでCodex一発で回せるレベルになってきました。
③ gpt-image-2 連携|画像生成・編集を同じワークフローで完結
先日リリースされた gpt-image-2 がCodexから使えるようになっています。
- アプリやダッシュボードのUIモックを生成
- プレゼンデッキ用の挿絵を生成
- 生成した画像を編集してバリエーションを作成
「コードを書く → UIモックを生成する → それを元にまたコードを書く」という往復が、Codex一つで完結するイメージです。
④ ファイル生成品質の向上|文書・スプレッドシート・スライド
文書・スプレッドシート・スライドといったファイルの生成品質も底上げされました。表計算やスライドを生成する精度が上がり、Codexアプリ内の新しいファイルビューアでその場で確認・修正できるようになっています。
「ChatGPTに資料作ってもらって、Officeに手動で移して整える」という面倒な往復が、かなり減りそうです。
料金・提供プラン
公開されている提供条件を整理します(API提供状況・料金は2026年7月時点の情報です)。
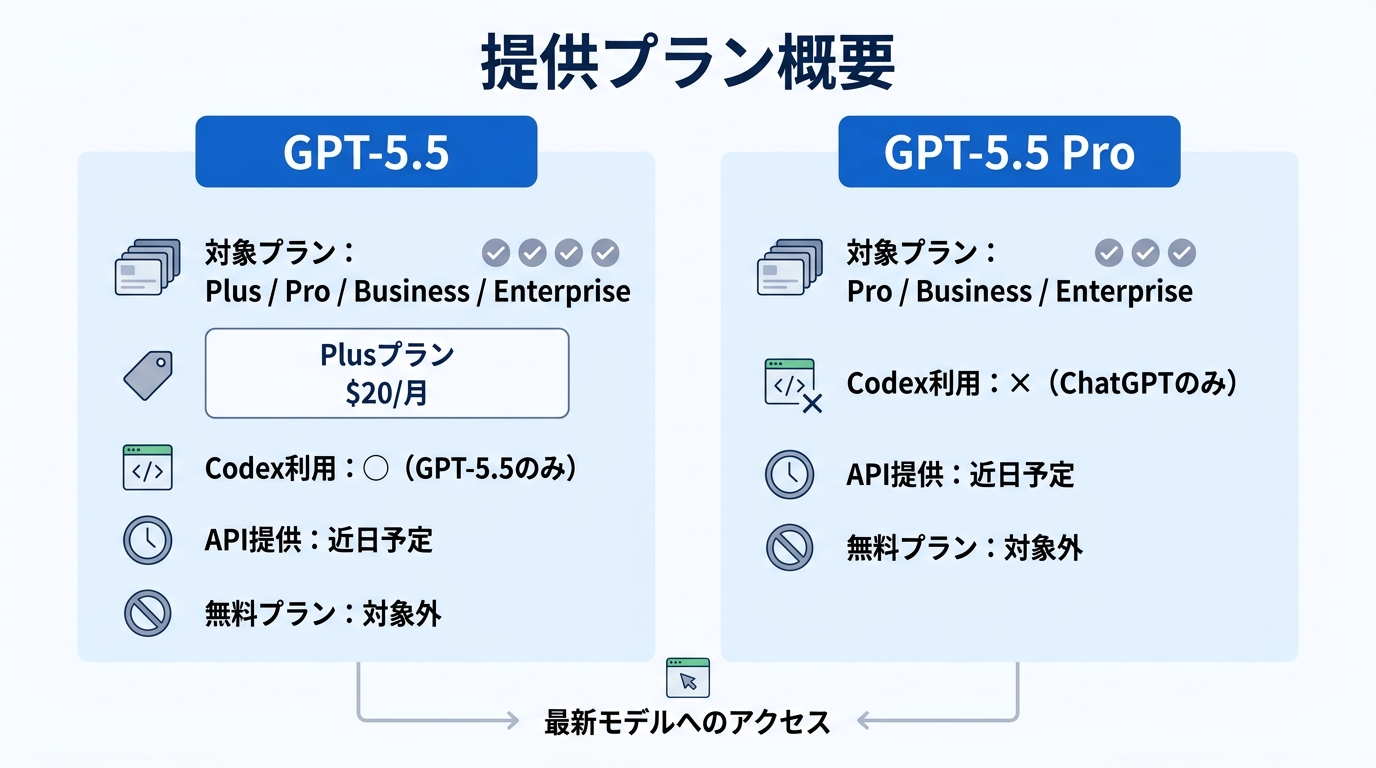
| 項目 | GPT-5.5 | GPT-5.5 Pro |
|---|---|---|
| 対象プラン | Plus / Pro / Business / Enterprise | Pro / Business / Enterprise |
| ChatGPT展開 | ◯ | ◯ |
| Codex展開 | ◯ | ×(ChatGPTのみ) |
| 無料プラン | 対象外 | 対象外 |
| API提供 | 提供中(入力 $5/出力 $30・100万トークン) | 提供中(入力 $30/出力 $180・100万トークン) |
Plus($20/月)でも GPT-5.5 が使えるのは大きなポイントですね。ChatGPT有料プランを使っていれば、追加課金なしで最新モデルにアクセスできます。
一方、GPT-5.5 Pro は上位プラン専用で、Codexでは使えません(ChatGPT内でのみ動作)。なお、GPT-5.5・GPT-5.5 Pro はいずれもOpenAI APIでも提供が始まっており、自社アプリやツールへの組み込みも可能です(料金は上表を参照)。
GPT-5.5を実務で使うべき3つのシナリオ
ベンチマーク数値を踏まえて、GPT-5.5が一番活きそうな使い方を3つ紹介します。
シナリオ①:Codexと組み合わせたコーディング自動化
Auto-reviewモードとブラウザ操作強化が加わったことで、「明日までにこのリポジトリの全テストを通して、依存関係を最新化して、PR作成まで済ませておいて」 のような依頼が、一晩で現実的になります。エンジニア個人の生産性というより、「プロジェクトのメンテナンス工数を大幅に圧縮する」使い方が刺さりそうです。
シナリオ②:リサーチ・データ分析のパートナーとして
BrowseComp 84.4%、FrontierMath Tier4 35.4%という数字が示すのは、ネット上の情報を集めて自分で裏付けを取りながら分析できる能力です。競合調査、業界トレンド分析、技術リサーチなど、これまで数時間かかっていた調べ物が、GPT-5.5 Proに任せれば数十分で質の高いアウトプットに変わる可能性があります。
シナリオ③:PC画面操作の自動化(定型PC作業の代替)
OSWorld 78.7%は、実際のPC画面を見てアプリを操作できる能力を示します。「このExcelファイルを開いて、特定の集計をして、別のシステムに入力する」といった定型業務を、RPA(ロボティック・プロセス・オートメーション。従来は専用ツールでPC操作を録画・再生して自動化していた仕組み)のような専用ツールなしで、AIに任せられる未来が見えてきました。
あなたの業務の中で 「人間がPCの前で同じ操作を繰り返している定型タスク」 が思い当たるなら、一度GPT-5.5 + Codexで自動化を試してみる価値があります。
今後の展望と注意点
サイバーセキュリティ評価が「High」扱い
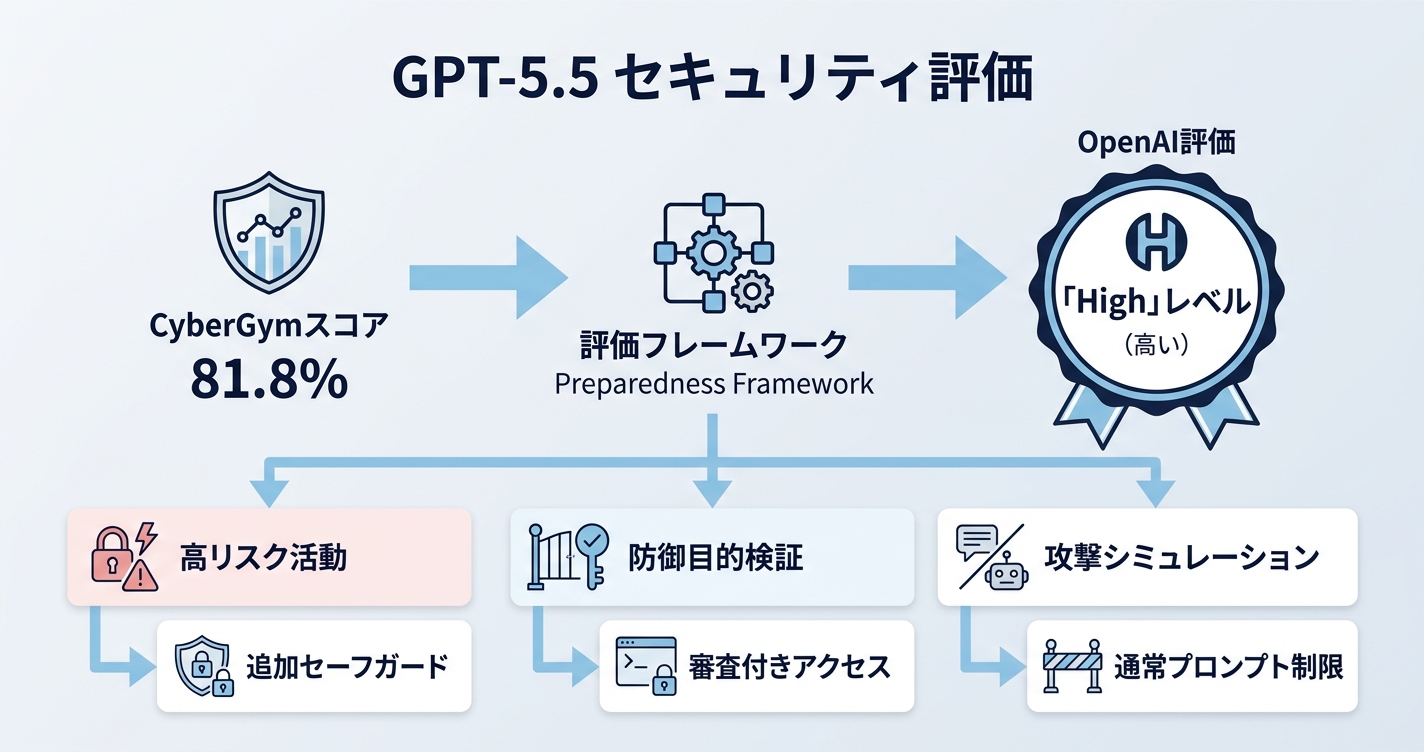
CyberGym 81.8%という高いスコアを受けて、OpenAIは GPT-5.5のサイバーセキュリティ能力を Preparedness Framework(OpenAIが自社モデルのリスクを段階評価している社内フレームワーク)上で「High」レベルに分類しています。高リスクなサイバー活動には追加のセーフガードがかかる一方で、防御目的の検証を行うチームには審査付きのアクセス枠(trusted access)も用意されているとのこと。
セキュリティ系の検証でGPT-5.5を使いたい場合、特に攻撃系のシミュレーションは通常のプロンプトでは弾かれる可能性があるので、事前にOpenAIの利用規約・使用ポリシーを確認しておくと安心です。
まとめ
今回のGPT-5.5は、単なる性能向上というより、「チャットAIの競争はもう次のステージに入った」という節目のリリースだと感じました。
- 5.4からの進化は、ターミナル自走・PC操作・科学研究・速度維持・トークン効率 の5方向
- 発表時点のClaude Opus 4.7を Terminal-Bench / OSWorld / BrowseComp / CyberGym / GDPval の5指標で上回った(現行のAnthropic上位モデルは後継のOpus 4.8)
- Codex側も Auto-review / ブラウザ操作 / gpt-image-2連携 / ファイル生成 で同時進化
- Plusプランでも利用可能で、OpenAI APIでも提供中(GPT-5.5・GPT-5.5 Pro とも)
- サイバーセキュリティは「High」評価で、一部の検証用途には追加セーフガードあり
なお、2026年6月末には次世代モデル GPT-5.6(Sol・Terra・Luna) の限定プレビューが始まっています。現時点(2026年7月)では一部のパートナー企業などへの限定提供にとどまっており、一般提供の正式な時期は案内されていません。GPT-5.5はそれまでの間、ChatGPT Plusプランで使える現行の主力モデルとして引き続き有効です。
あなたの業務で 「いつも人間がPCの前で繰り返している定型タスク」 を1つ洗い出して、GPT-5.5 + Codexで自動化を試してみるところから始めてみてください。きっと、実務AIの進化を実感できるはずです。
とはいえ、「GPT-5.5・Claude・Geminiを業務のどこに、どう組み込むか」 を自社だけで判断するのは簡単ではありませんよね。モデル進化のスピードに合わせて最適解も変わり続けています。
デジライズでは、GPT-5.5をはじめとする最新の生成AIを活用した導入研修を行っています。まずはミーティングにてあなたの職場の業務内容をヒアリングし、現場で価値を発揮するAI活用法を一緒に形にしていきます。AIの専門家が実務への定着まで伴走しますので、社内に専門のIT担当者がいなくても安心して進められます。
「まずは何ができるか知りたい」といった情報収集段階でのご相談も歓迎です。以下より資料を無料でダウンロードいただけますので、お気軽にご活用ください。
この記事の著者 / 編集者

