





「AIに嘘をつかれた経験、ありませんか?」
ChatGPTに質問したら、それっぽい顔をして完全に間違った情報を返してきた。調べてみたら、そんな事実どこにも存在しない──こんな経験をした人は少なくないはずです。
私自身、日々の業務でAIを使い倒している中で、このハルシネーション問題には何度も頭を悩まされてきました。特に法人向けの業務や、正確性が求められる調査タスクでは、AIが自信満々に嘘をつくのは本当に困ります。
そんな中で、Claudeを使い始めてから「あれ、このAI、なんか違うな」と感じることが増えました。知らないことは「わかりません」と正直に言うし、不確かな情報には「確信が持てません」と前置きする。
これ、実は偶然じゃないんです。Claudeには「Constitutional AI(憲法的AI)」という独自の設計思想が組み込まれていて、それが「嘘をつきにくさ」の根本にある。
今回は、このConstitutional AIの仕組みを深掘りしながら、なぜClaudeがハルシネーション(AIの嘘)を抑制できるのか、その本質に迫っていきます。
最新AIトレンドをキャッチアップ!
メルマガ登録はこちら
目次
Claudeの新Constitutionとは何か
Constitutional AIの基本概念
まず、Constitutional AI(CAI)が何なのか、基本から押さえておきましょう。
簡単に言うと、AIに「憲法」を与えて、自分自身の出力を評価・修正させる仕組みです。
従来のAI訓練では、RLHF(Reinforcement Learning from Human Feedback)という手法が主流でした。これは人間がAIの出力を評価して、「これは良い回答」「これはダメな回答」とフィードバックを与えて学習させる方法です。
でも、RLHFには問題があります。人間のフィードバックを大量に集めるのはコストがかかるし、評価者によって基準がバラバラになりがち。そして何より、なぜその判断をしたのかが不透明になりやすい。
Constitutional AIは、この問題を「憲法」というアプローチで解決しようとしています。
具体的には、AIに原則のセット(憲法)を与えて、自分自身の出力を評価させます。「この回答は憲法に照らして適切か?」とAI自身に問いかけさせ、問題があれば自己修正させる。
これによって、透明性とスケーラビリティの両方を確保できるわけです。なぜAIがその判断をしたのかが「憲法」という形で明文化されているし、人間のフィードバックに頼らずにスケールできる。
Claudeの新しい憲法の公開背景
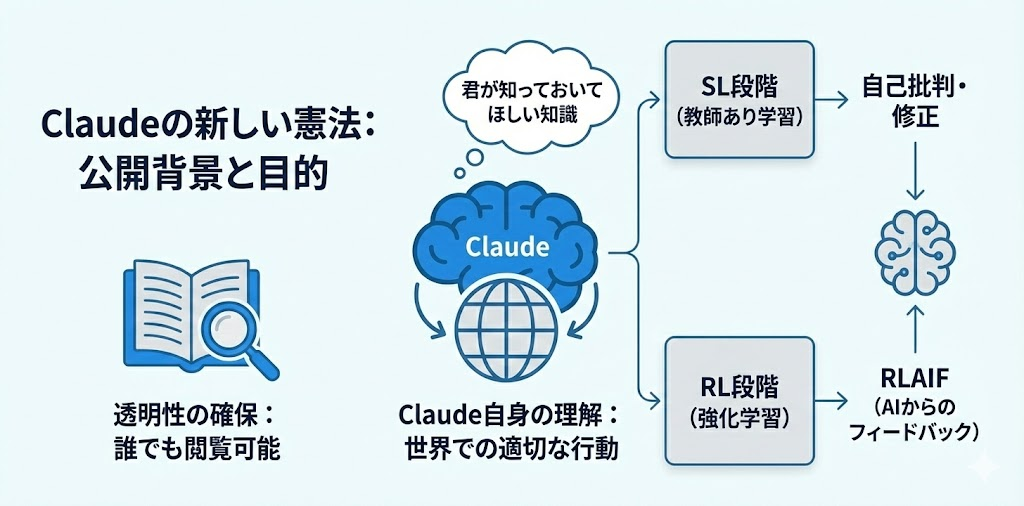
2026年1月、Anthropicは大幅に刷新された新しい「憲法」を公開しました。
普通、AIの訓練に使われる内部ルールや評価基準は企業秘密として隠されることが多いです。しかし、Anthropicは、Claudeがどんな価値観で動いているのかを、誰でも読める形で公開しました。
面白いのは、この憲法が「Claude自身のために」書かれているという点です。
普通、AIのガイドラインは「AIはこうあるべき」という外部からの規定という形で書かれます。ただしClaudeの憲法は、Claude自身が世界で適切に行動するために必要な知識と理解を与えることを意図して書かれています。
つまり、「お前はこうしろ」ではなく、「君がこの世界で正しく振る舞うために、これを知っておいてほしい」というスタンスです。
訓練プロセスでは、この憲法が2段階で活用されます。
SL段階(教師あり学習):初期モデルから回答を生成させて、憲法に基づいて自己批判・修正を行い、その修正された回答でモデルを微調整します。
RL段階(強化学習):微調整されたモデルから回答を生成し、AIの好みデータセットから好みモデルを訓練。これを報酬信号として使います(RLAIF: AI Feedback からの強化学習)。
4つの優先事項の階層構造
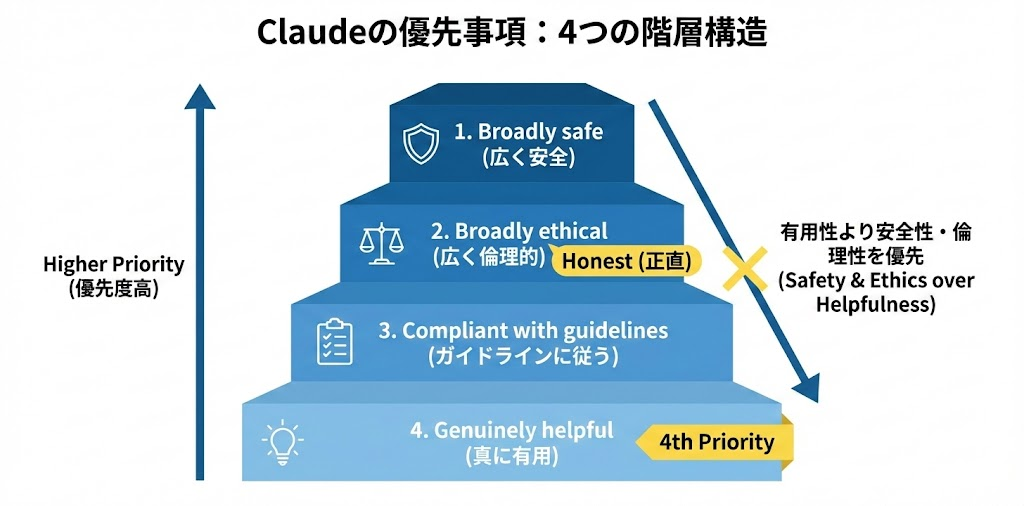
Claudeの憲法で特に重要なのが、4つの優先事項の階層構造です。
- Broadly safe(広く安全):適切な人間によるAI監督メカニズムを損なわない
- Broadly ethical(広く倫理的):正直で、良い価値観に従い、不適切・危険・有害な行動を避ける
- Compliant with Anthropic’s guidelines(Anthropicのガイドラインに従う)
- Genuinely helpful(真に有用):対話する運用者とユーザーに利益をもたらす
この順番が重要です。「有用であること」は4番目なんです。
他のAIだと「ユーザーの役に立つこと」が最優先になりがち。でもClaudeは、安全性と倫理性を有用性より上に置いています。
これが「嘘のつきにくさ」にどう影響するか?
2番目の「Broadly ethical」に「正直であること」が含まれています。つまり、たとえユーザーが喜ぶ回答であっても、それが嘘なら出してはいけないという優先順位になっています。
「ユーザーを満足させたい」という動機で嘘をつくことが、設計レベルで抑制されているわけです。

Claude Skillsとは?仕事を変えるAI×人の共同制作|活用事例とセキュリティ解説
ハルシネーションは「モデル性能」ではなく「設計思想」の問題
ハルシネーション(Confabulation)の定義
ここで、ハルシネーションの定義をちゃんと押さえておきましょう。NISTのAI Risk Management Framework(AI 600-1)では、これを“Confabulation”と呼んでいます。定義としては、「GAI(生成AI)システムが誤った内容を自信を持って提示する現象」です。
重要なのは、これが生成モデルの設計方法の自然な結果だという点です。
生成AIは、訓練データの統計分布を近似するように作られています。「次に来そうな単語」を予測し続けることで文章を生成する。だから、事実的に正確な出力と不正確な出力の両方を生成しうる。つまり、ハルシネーションは「バグ」ではなく「仕様」に近く、生成モデルである以上、構造的に避けられない問題なんです。
だからこそ、設計思想レベルでの対策が重要になってきます。
Constitutional AIがハルシネーションを抑制する仕組み
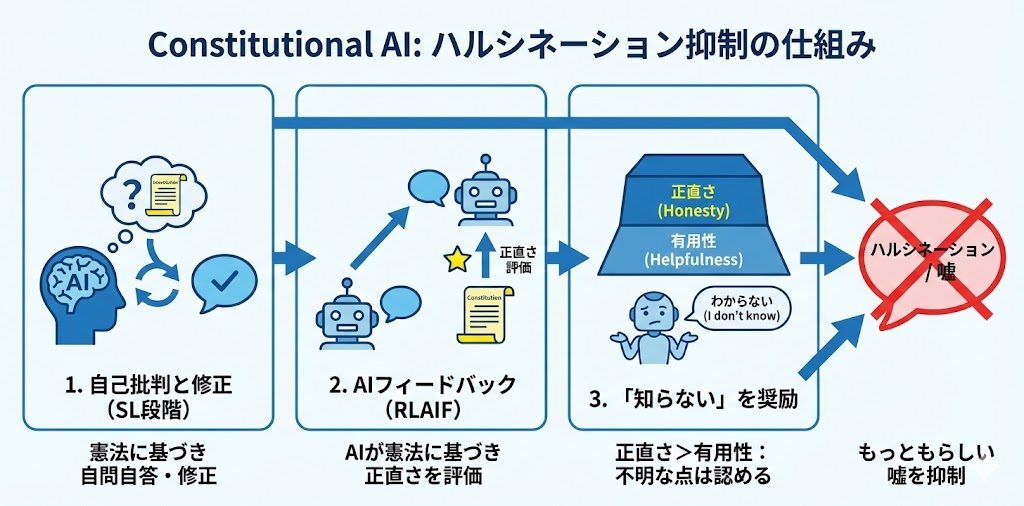
Constitutional AIは、この構造的な問題に対して、いくつかの仕組みで対処しています。
1. 自己批判と修正プロセス(SL段階)
Claudeは回答を生成した後、憲法に基づいて自分の回答を批判します。「この回答は正確か?」「根拠のない主張をしていないか?」と自問自答し、問題があれば修正する。このプロセスが訓練段階で繰り返されることで、「怪しい情報を自信満々に言い切る」という傾向が抑制されます。
2. AIフィードバックによる強化学習(RLAIF)
RLHFでは人間がフィードバックを与えますが、RLAIFではAI自身がフィードバックを生成します。このとき、憲法に基づいて「正直な回答」を高く評価するように設計されています。結果として、「嘘をついても評価される」という学習が起きにくくなるというわけです。
3. 「知らない」と正直に言うことを奨励する設計
これが一番大きいかもしれません。多くのAIは「ユーザーの質問に答える」ことを最優先にしています。だから、知らないことでも何か答えようとする。結果、もっともらしい嘘が生まれる。
Claudeの憲法では、正直さが有用性より上位に置かれています。だから、「わからないことはわかからないと言う」ことが、設計レベルで奨励されている。
TruthfulQAでの実証結果
この設計思想の効果は、ベンチマークでも確認されています。TruthfulQAは、AIの真実性を測定するためのベンチマークです。人間が間違いやすい質問(都市伝説や誤解に基づく質問など)を投げて、AIが正確に答えられるかをテストします。
Claudeファミリーのモデルは、このベンチマークにおいて他の主要LLMと比較して高いスコアを示す傾向があります。
もちろん、ベンチマークは万能ではありません。しかし、Constitutional AIの設計思想が実際に効果を発揮していることを示す一つの証拠にはなります。

Claude CodeのAI主導サイバー攻撃から学ぶ:企業が見直すべき生成AIセキュリティ戦略
Constitutional AIはハルシネーションをどこまで抑制できるのか
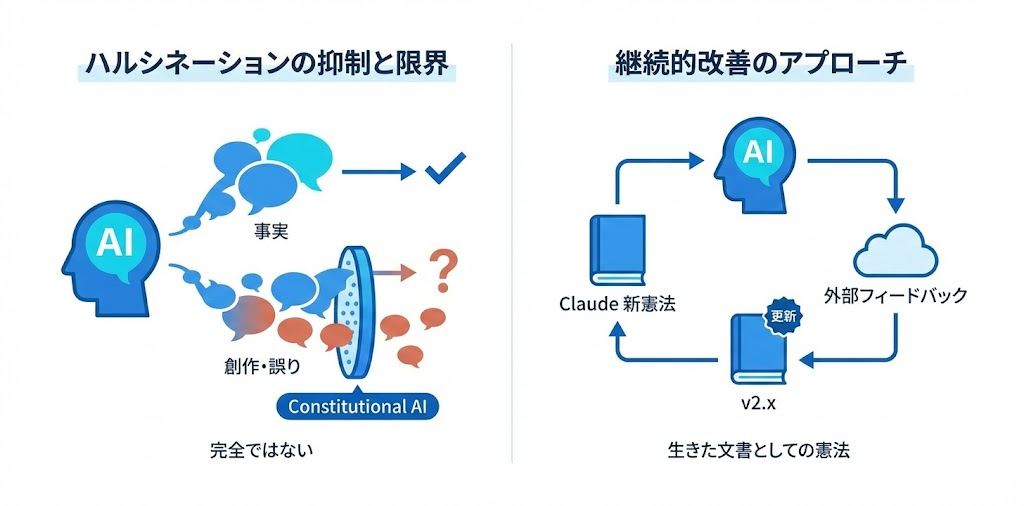
現在の限界と課題
ここまで読むと「Claudeは嘘をつかない完璧なAI」みたいに聞こえるかもしれませんが、そんなことはありません。
Claude Opus 4.5のSystem Cardを見ると、Confabulation(ハルシネーション)のリスクは依然として存在すると明記されています。
特に課題として挙げられているのは以下の点です。
- 長文生成:文章が長くなるほど、事実と創作が混ざりやすくなる
- 専門ドメイン:訓練データが少ない分野では、不正確な情報を生成しやすい
- 複雑な推論:複数のステップを経る推論では、途中で誤りが入り込みやすい
Constitutional AIは万能薬ではありません。あくまで「嘘をつきにくくする」設計であって、「嘘を完全に防ぐ」設計ではないんです。
継続的改善のアプローチ
Anthropicはこの限界を認識した上で、継続的な改善に取り組んでいます。
特徴的なのは、憲法を「生きた文書」として位置づけていることです。一度決めたら終わりではなく、新しい課題が見つかれば更新する。外部の専門家からフィードバックを受けて、憲法自体を改善していく。「完璧なルールを作る」のではなく、「ルールを継続的に改善するプロセスを作る」というアプローチです。
【更新を見逃したくない方へ】
「情報を追いたいけど時間がない」――そんな方に向けて、重要AIニュースを毎週配信中です。
1週間のAIニュースを厳選し、3分で要点がつかめる形にまとめています。業務の手を止めずに、最低限押さえるべき内容を把握できます。
重要AIニュースを毎週キャッチアップ
無料で受け取る
他の主要LLMと思想レベルで比較すると何が違うのか
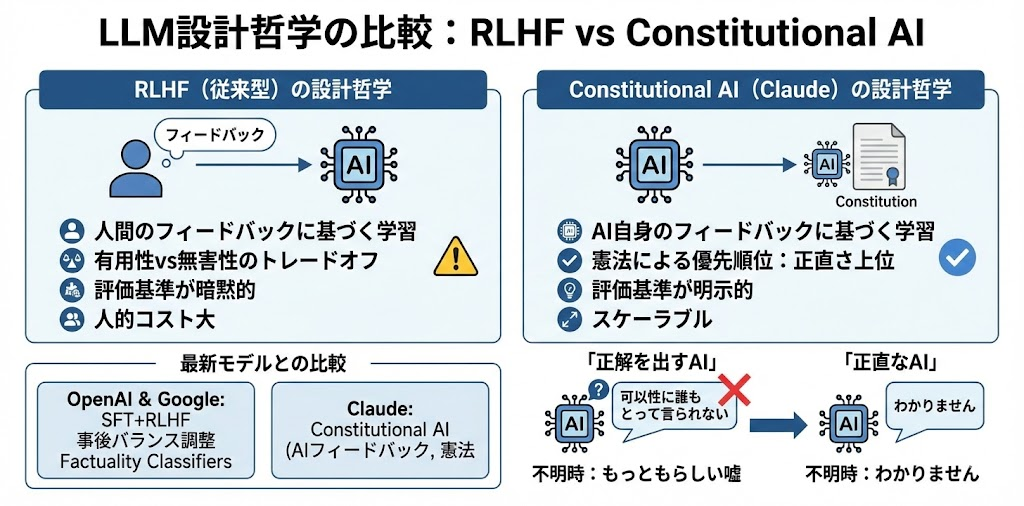
RLHF vs Constitutional AIの設計哲学
ここで、Constitutional AIと従来のRLHFの設計哲学の違いを整理しておきましょう。
RLHF(従来型)の特徴
- 人間のフィードバックに基づいて学習
- 「有用性 vs 無害性」のトレードオフが発生しやすい
- 評価基準が暗黙的(なぜその判断をしたかが不透明)
- スケーリングに人的コストがかかる
Constitutional AI(Claude)の特徴
- AI自身のフィードバックに基づいて学習
- 憲法による優先順位で「正直さ」を上位に
- 評価基準が明示的(憲法として公開)
- スケーラブル(人間のフィードバック不要)
最新モデルとの比較視点
OpenAIの最新モデル(GPT-5シリーズ)やGoogleの最新LLM(Gemini 3シリーズ等)も、それぞれ安全性設計に取り組んでいます。
OpenAIはsupervised fine-tuningとRLHFを組み合わせて安全性を向上させています。有用性と無害性のバランスをpost-trainingで調整するアプローチです。
Googleの最新LLMは、RLHF-inspiredな手法でsafety tuningを行い、ハルシネーション低減のためにfactuality classifiersやsynthetic dataを活用しています。
ここで重要なのは、「正解を出すAI」と「正直なAI」は違うということです。多くのAIは「正解を出す」ことを目指しています。ユーザーの質問に正確に答える。でも、正解がわからないときにどうするか?
- 「正解を出すAI」は、何か答えを出そうとします。結果、もっともらしい嘘が生まれる。
- 「正直なAI」は、わからないときは「わかりません」と言う。正解率は下がるかもしれませんが、嘘は減る。
Constitutional AIは、後者の設計思想を取っています。
法人・業務利用でClaudeが向いているケース
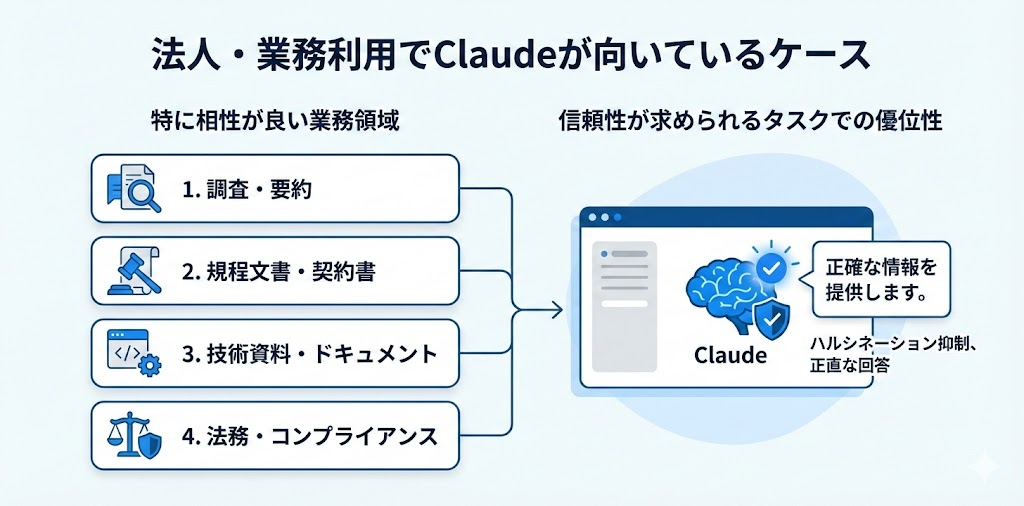
特に相性が良い業務領域
ここまでの話を踏まえて、Claudeが特に向いている業務領域を考えてみましょう。
1. 調査・要約
ハルシネーションが抑制されているので、リサーチ業務との相性が良いです。「知らないことは知らない」と言ってくれるから、情報の信頼性を判断しやすいです。
2. 規程文書・契約書の作成
正確性が求められる文書作成。嘘が混じると致命的な分野で、Claudeの「正直さ」が活きます。
3. 技術資料・ドキュメント作成
コーディングやデバッグでの実務活用でも、Claudeは評価が高いです。「動くけど間違ってるコード」を出しにくい設計が効いてきます。
4. 法務・コンプライアンス関連
不正確な情報がリスクになる分野です。Claudeの保守的な姿勢が、かなりメリットとしてはたらきます。
信頼性が求められるタスクでの優位性
開発者コミュニティでの評価を見ても、「Claudeは嘘をつきにくい」という認識は広まっているようです。
特にコーディングタスクでは、「ChatGPTは自信満々に間違ったコードを出すことがあるけど、Claudeは『この部分は確認が必要です』と前置きしてくれる」という声をよく聞きます。
これは、Constitutional AIの「正直さを優先する」設計が、実務レベルで効果を発揮している証拠だと思います。
導入時の注意点
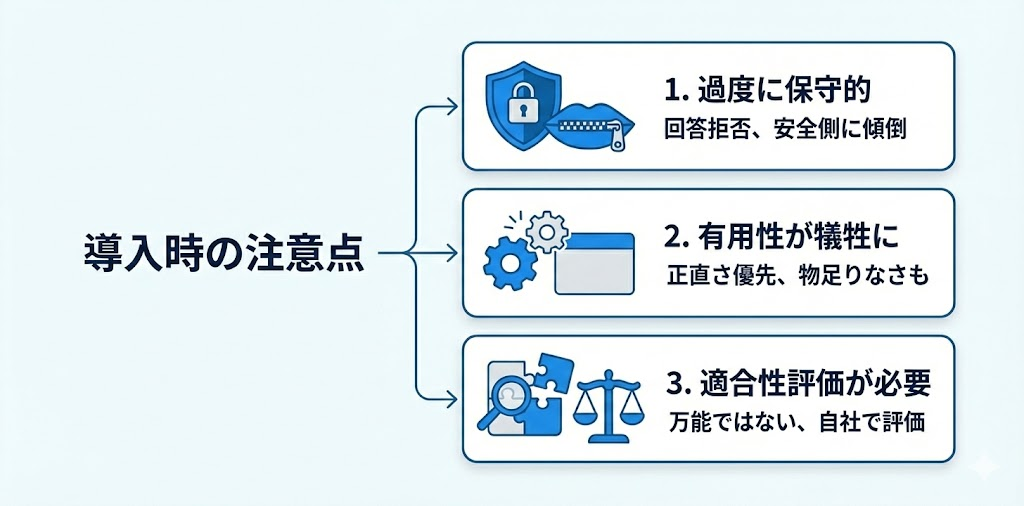
ただし、注意点もあります。
1. 過度に保守的になることがある
憲法の優先順位が安全側に傾いているため、「それは答えられません」と言われることが他のAIより多いかもしれません。ユースケースによっては、これがストレスになることもあるでしょう。
2. 有用性が犠牲になるケースがある
「正直さ > 有用性」という優先順位なので、「とにかく何か答えてほしい」という場面では物足りなく感じることもあります。
3. ユースケースごとの適合性評価が必要
万能ではないので、自社の業務に本当に合っているかは、実際に試して評価する必要があります。
まとめ
信頼できるAIの本質は、単に正解を出すことではなく「正直であること」にあります。Claudeがハルシネーション(嘘)を起こしにくいのは、モデルの性能差だけではなく、「Constitutional AI」という設計思想が根底にあるからです。「正直さ」を「有用性」より優先し、自ら間違いを修正し、「知らない」と認めるよう設計されたこのプロセスこそが、ビジネスにおける信頼の根幹を支えています。
しかし、重要なのはあくまで「嘘をつきにくい」だけであり、決して完璧ではないという点です。AIの安全性や技術は日々進化しているため、ビジネスの現場では、こうした各モデルの特性や限界を正しく理解し、自社の業務に最適化して組み込む知見が不可欠となります。
デジライズでは、こうした最新モデルの特性も踏まえた生成AIの導入研修を行っています。ミーティングで業務内容をヒアリングし、現場で本当に使えるAI活用法を一緒に考えるところからスタートします。実際に業務で使えるよう、AIの専門家が伴走いたしますので、AI担当者がいない企業様でもご安心ください。
まずは情報収集からでも歓迎です。導入の流れや支援内容をまとめた資料をこちらからご覧いただけます。

参考URLリスト
Anthropic「Claude’s new Constitution」(最新版の憲法):https://www.anthropic.com/news/claude-new-constitution
Constitutional AI 論文(arXiv):https://arxiv.org/abs/2212.08073
Anthropic「Claude Opus 4.5 System Card」:https://www.anthropic.com/claude-opus-4-5-system-card
OpenAI「Models」(最新モデル一覧):https://platform.openai.com/docs/models
Google「Gemini models」(最新モデル一覧):https://ai.google.dev/gemini-api/docs/models
NIST AI 600-1(AI Risk Management Framework):https://nvlpubs.nist.gov/nistpubs/ai/NIST.AI.600-1.pdf
