






目次
はじめに
2025年4月15日、OpenAIが待望の新モデル「GPT-4.1」を発表しました。従来のGPT-4およびGPT-4oから大幅に進化したこのモデルは、コーディング能力、指示遵守性、そして長文理解能力において飛躍的な向上を見せています。特に注目すべきは、最大100万トークンという前例のない長さのコンテキスト処理能力と、コスト効率の大幅な改善です。
サム・アルトマンCEOは自身のXアカウントで「GPT-4.1(および-miniと-nano)がAPIで利用可能になりました!これらのモデルはコーディング、指示追従、長文コンテキスト(100万トークン)に優れています。ベンチマークは強力ですが、私たちは実世界での有用性に焦点を当て、開発者は非常に満足しているようです。GPT-4.1ファミリーはAPI専用です」と発表しています。
本記事では、GPT-4.1の特徴、性能、活用法について詳細に解説するとともに、実際のベンチマーク結果や事例をもとに、このモデルがもたらす可能性と影響を探ります。
GPT-4.1ファミリーの全容
OpenAIは今回、3つの異なるモデルを「GPT-4.1ファミリー」として同時に発表しました。それぞれのモデルは異なる用途と予算に対応しています。

GPT-4.1(標準モデル)
OpenAIの主力となる最高性能モデルです。コーディング、指示遵守、長文処理のすべてにおいて卓越した性能を持ち、学術知識から実践的なタスクまで幅広く対応します。料金は入力1Mトークンあたり2.00ドル、出力8.00ドルと、GPT-4oより約26%低コストでありながら、より高い性能を発揮します。
本モデルの特徴は「日本語の表現力」が特に優れていると評価されており、翻訳、文章作成、編集タスクで特に効果を発揮します。また、最大32,768トークンの出力に対応し、GPT-4oの16,384トークンから大幅に拡張されています。
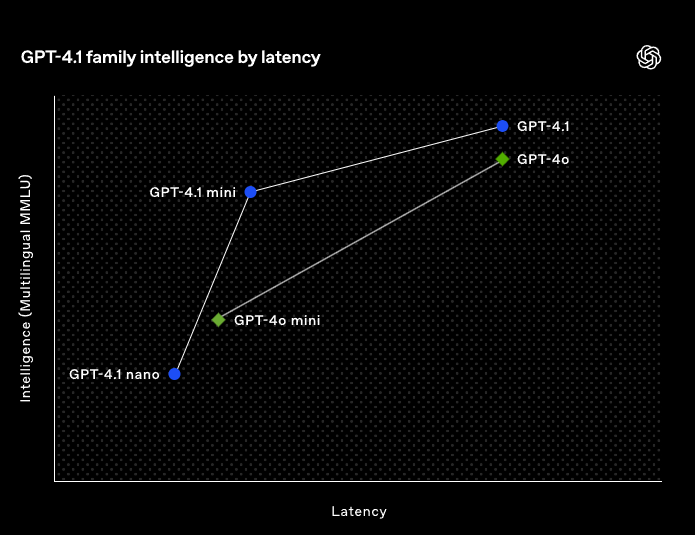
GPT-4.1 mini
標準モデルとほぼ同等の知能を持ちながら、レイテンシ(応答速度)を約半分に短縮し、コストを83%も削減した中間モデルです。多くのベンチマークでGPT-4oを上回る性能を示しており、コスト効率を重視するユーザーに最適です。
入力1Mトークンあたり0.40ドル、出力1.60ドルという低価格でありながら、MMLU(多様な知識を測るベンチマーク)で87.5%、MathVista(数学の視覚問題)で73.1%というハイスコアを記録しています。
GPT-4.1 nano
OpenAI史上最速・最も低コストなモデルで、それでいて100万トークンのコンテキスト処理能力を持っています。MMLUベンチマークで80.1%のスコアを達成するなど、小型モデルながら高い知能を示しており、主に分類や自動補完などの低レイテンシが求められるタスクに最適です。
入力1Mトークンあたり0.10ドル、出力0.40ドルという破格の料金設定は、大量のデータ処理や高頻度のAPIコールが必要なアプリケーションにとって画期的です。
GPT-4.1の核心!進化した5つのポイント
GPT-4.1は多くの面で目覚ましい進化を遂げていますが、特に注目すべき点は以下の5つです。
1. 超長文理解力:100万トークン対応
GPT-4.1の最も革新的な特徴は、最大100万トークンという驚異的な長さのコンテキストを処理できる能力です。これはGPT-4oの128,000トークン(約12.8万トークン)と比較して約8倍の拡張であり、一度に膨大な量のテキストを読み込み、処理することが可能になりました。
具体的なイメージとしては:
- レオ・トルストイの「戦争と平和」(約55万語)を1回の会話で処理可能
- Reactのソースコード全体を8つ分同時に読み込める容量
- 法律文書や技術仕様書数百ページを一度に分析可能
OpenAIが公開した「Needle in a Haystack」評価では、GPT-4.1はコンテキスト内のどの位置に埋め込まれた情報でも正確に抽出できることが示されています。
このような長文理解能力は、法務、研究、金融などの分野で特に有用です。例えば、Thomson Reutersの検証では、法務文書の複数文書レビュー精度が17%向上し、Carlyle社では財務データ抽出の精度が50%向上したと報告されています。
2. コーディング能力の飛躍的向上
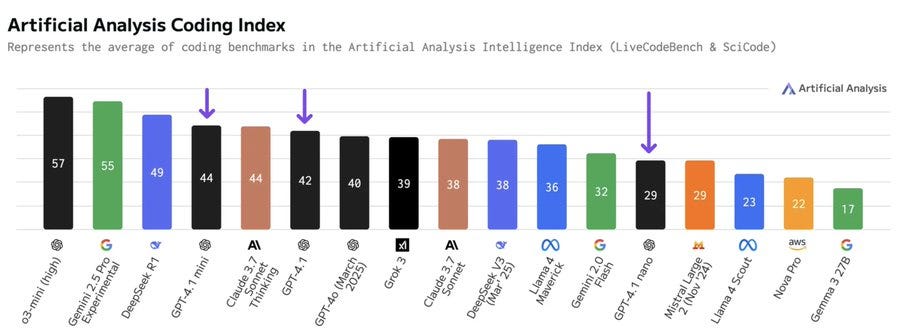
GPT-4.1はコーディング能力において大幅な向上を見せています。ソフトウェアエンジニアリング能力を測るベンチマーク「SWE-bench Verified」では54.6%のスコアを記録し、GPT-4oの33.2%から21.4ポイントもの向上を達成しました。
Aiderのポリグロット差分ベンチマークでは、GPT-4.1はGPT-4oのスコアを倍以上に向上させ、さらにGPT-4.5をも8ポイント上回る性能を示しています。特に差分形式でのコード出力では、GPT-4.1が52.9%のスコアを達成し、GPT-4oの18.2%から大幅に向上しています。
実際の開発環境での評価では、人間の評価者によるとGPT-4.1が作成したウェブサイトはGPT-4oのものより80%の確率で好まれるという結果が出ています。また、OpenAIの内部評価では、コードへの不要な編集がGPT-4oの9%からGPT-4.1では2%に減少したことが報告されています。
この進化により、GPT-4.1は以下のような高度なコーディングタスクに対応できるようになりました:
- リポジトリ全体の探索と理解
- 複雑なバグの特定と修正
- 一貫性のあるフロントエンド開発
- 指定された形式に準拠したコード生成
- 大規模コードベースの分析と最適化提案
3. マルチモーダル理解の強化
GPT-4.1ファミリーは画像認識能力も大幅に向上しています。特にGPT-4.1 miniは「MMMU」画像ベンチマークで75%という高いスコアを達成し、GPT-4oを上回る性能を示しています。
視覚的質問応答能力を測る主要なベンチマーク結果は以下の通りです:
| ベンチマーク | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o | GPT-4.5 |
|---|---|---|---|---|---|
| MMMU | 74.8% | 72.7% | 55.4% | 68.7% | 75.2% |
| MathVista | 72.2% | 73.1% | 56.2% | 61.4% | 72.3% |
| CharXiv-R | 56.7% | 56.8% | 40.5% | 52.7% | 55.4% |
| CharXiv-D | 87.9% | 88.4% | 73.9% | 85.3% | 90.0% |
特に注目すべきは「Video-MME」ベンチマークで、GPT-4.1が長尺動画理解カテゴリ(字幕なし)で72.0%のスコアを獲得し、GPT-4oの65.3%から6.7ポイントの向上を見せました。これにより、30分から1時間程度の動画内容を理解し、それに基づいた質問に答えることが可能になっています。
この視覚能力の強化は、以下のような応用を可能にします:
- 技術図面や設計図の詳細な分析
- 医療画像の説明と所見の補助
- 監視映像からの異常検知
- グラフや図表を含む複雑な報告書の理解と要約
- 講義やプレゼンテーション動画の内容理解と質疑応答
4. 高性能かつ低コスト
GPT-4.1シリーズはパフォーマンスの向上だけでなく、コスト効率も大幅に改善されています。GPT-4.1はGPT-4oと比較して使用コストが約26%削減され、さらに高速化も実現。特にGPT-4.1 miniはGPT-4oとほぼ同等の性能を持ちながら、コストは83%も削減されています。
各モデルの詳細な料金体系は以下の通りです:
| モデル | 入力コスト(1Mトークンあたり) | 出力コスト(1Mトークンあたり) | ブレンド価格 | キャッシュ入力割引 |
|---|---|---|---|---|
| GPT-4.1 | 2.00ドル(約290円) | 8.00ドル(約1100円) | 1.84ドル(約260円) | 0.50ドル(約72円) |
| GPT-4.1-mini | 0.40ドル(約57円) | 1.60ドル(約230円) | 0.42ドル(約60円) | 0.10ドル(約14円) |
| GPT-4.1-nano | 0.10ドル(約14円) | 0.40ドル(約53円) | 0.12ドル(約17円) | 0.025ドル(約3.6円) |
同じプロンプトを繰り返し使用する場合のキャッシュ割引も75%(従来は50%)に拡大され、長文コンテキストを扱う際のコスト効率が大幅に向上しています。また、バッチAPIを使用すると、さらに50%の追加割引が適用されます。
応答速度に関しても大幅な改善が見られ、OpenAIの発表によると:
- GPT-4.1は12.8万トークンのコンテキストで約15秒、100万トークンで約1分の初回トークン生成時間
- GPT-4.1 miniはさらに高速で、GPT-4oと比較して約50%の速度向上
- GPT-4.1 nanoは12.8万トークンのコンテキストでも5秒以内に初回トークンを返す超高速モデル
この価格性能比の向上により、中小企業やスタートアップ、個人開発者でも最先端AIを実用的なコストで利用できるようになりました。
5. 指示遵守能力の向上
GPT-4.1は指示に従う能力も大幅に向上しています。Scale’s MultiChallengeベンチマークでは38.3%のスコアを記録し、GPT-4oより10.5ポイント向上しました。これにより、複雑な指示や多段階のタスクをより正確に処理できるようになっています。
OpenAIの内部評価では、特に以下の分野での指示遵守能力の向上が確認されています:
- フォーマット指定: XML、YAML、Markdown等の指定形式での出力精度の向上
- 否定的指示: 「〜しないでください」といった禁止事項の遵守率向上
- 順序付き指示: 複数のステップを正確な順序で実行する能力
- 内容要件: 指定された情報を必ず含めるといった要件の遵守
- ランキング: 出力を特定の基準で順序付ける正確性
- 過剰自信の抑制: 分からないことに対して「わからない」と正直に答える能力
IFEval(指示遵守評価)では87.4%のスコアを記録し、GPT-4oの81.0%から6.4ポイントの向上を見せています。Multi-IF評価でも70.8%を達成し、GPT-4oの60.9%を大きく上回っています。
この指示遵守能力の向上は、特にエンタープライズ環境で重要です。正確なフォーマット遵守、指定されたルールの厳守、多段階タスクの正確な実行などが求められるビジネス環境において、GPT-4.1はより信頼性の高いツールとして機能します。
GPT-4.1と従来モデルとの詳細比較
GPT-4.1が従来のモデルと比較してどのように進化したのか、各側面から詳しく見ていきましょう。
学術知識と汎用知能
GPT-4.1は学術知識と汎用知能においても着実な進化を遂げています。
| ベンチマーク | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o | GPT-4.5 |
|---|---|---|---|---|---|
| MMLU | 90.2% | 87.5% | 80.1% | 85.7% | 90.8% |
| 多言語MMLU | 87.3% | 78.5% | 66.9% | 81.4% | 85.1% |
| GPQA Diamond | 66.3% | 65.0% | 50.3% | 46.0% | 69.5% |
| AIME ’24 | 48.1% | 49.6% | 29.4% | 13.1% | 36.7% |
特にGPQA(高度な専門知識を問う質問集)では、GPT-4.1は66.3%のスコアを達成し、GPT-4oの46.0%から20ポイント以上の大幅な向上を見せています。また、数学オリンピックレベルの問題集AIME ’24でも、GPT-4.1は48.1%のスコアを記録し、GPT-4oの13.1%から35ポイントもの飛躍的向上を達成しています。
こうした進化は、GPT-4.1が単純な質問応答だけでなく、高度な推論や複雑な問題解決においても大きく能力を向上させたことを示しています。
コーディング能力の詳細分析
コーディング能力はGPT-4.1の最も顕著な進化点の一つです。各種ベンチマークの詳細な結果を見てみましょう。
| ベンチマーク | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o | GPT-4.5 |
|---|---|---|---|---|---|
| SWE-bench Verified | 54.6% | 23.6% | – | 33.2% | 38.0% |
| SWE-Lancer | $176K (35.1%) | $165K (33.0%) | $77K (15.3%) | $163K (32.6%) | $186K (37.3%) |
| SWE-Lancer (IC-Diamond) | $34K (14.4%) | $31K (13.1%) | $9K (3.7%) | $29K (12.4%) | $41K (17.4%) |
| Aider’s polyglot: whole | 51.6% | 34.7% | 9.8% | 30.7% | – |
| Aider’s polyglot: diff | 52.9% | 31.6% | 6.2% | 18.2% | 44.9% |
SWE-bench Verifiedでの大幅な性能向上(54.6% vs GPT-4oの33.2%)は、GPT-4.1が実際のソフトウェア開発環境で大きな効果を発揮することを示しています。このベンチマークでは、モデルにコードリポジトリと課題の説明が与えられ、問題を修正するためのパッチを生成する能力が測定されます。GPT-4.1は単にコードを生成するだけでなく、大規模なコードベースを理解し、テストを通過する実行可能なコードを書く能力が大幅に向上しています。
Aiderのポリグロット差分ベンチマークでの大幅な向上(diff形式で52.9% vs GPT-4oの18.2%)は、特に実務的な価値が高いです。これはモデルが様々なプログラミング言語でコードの変更を正確に生成できるかを測定するもので、GPT-4.1は特にdiff形式(変更のみを出力する形式)での性能が大幅に向上しています。これにより、大規模なコードファイルの編集が効率化され、コストとレイテンシの削減が可能になります。
Windsurf社の事例によると、実際の開発環境での効果として:
- コード変更の初回レビュー通過率が60%向上
- ツール呼び出しの効率が30%向上
- 不要なコード編集の繰り返しが50%減少
- コードの理解度と探索効率が大幅に向上
長文理解能力の実用価値
GPT-4.1の100万トークンというコンテキスト長は、理論上の数字以上の実用価値を持っています。OpenAIは新たにいくつかの長文理解能力評価指標を公開し、GPT-4.1の性能を検証しています。
| 評価 | GPT-4.1 | GPT-4.1 mini | GPT-4.1 nano | GPT-4o | GPT-4.5 |
|---|---|---|---|---|---|
| OpenAI-MRCR: 2 needle 128k | 57.2% | 47.2% | 36.6% | 31.9% | 38.5% |
| OpenAI-MRCR: 2 needle 1M | 46.3% | 33.3% | 12.0% | – | – |
| Graphwalks bfs <128k | 61.7% | 61.7% | 25.0% | 41.7% | 72.3% |
| Graphwalks bfs >128k | 19.0% | 15.0% | 2.9% | – | – |
OpenAI-MRCRは、コンテキスト内に複数の類似した要素がある中から特定の情報を見つけ出す能力を測定するテストです。例えば、「3番目のタピルについての詩を教えて」といった指示に正確に応えられるかを評価します。GPT-4.1は128Kトークンの文脈では57.2%のスコアを達成し、GPT-4oの31.9%を大きく上回っています。
GraphwalksはOpenAIが今回新たに公開したベンチマークで、コンテキスト内の複数の位置を参照する必要がある複雑な推論タスクを評価します。これは単線的な読解ではなく、グラフ構造のような複雑なデータを理解し、その中を「歩き回る」能力を測ります。GPT-4.1は128K未満のコンテキストで61.7%のスコアを達成し、GPT-4oの41.7%を大きく上回っています。
実用事例:GPT-4.1の現場での効果
GPT-4.1の実力は理論上のベンチマークだけでなく、実際のビジネス現場での活用事例からも明らかです。OpenAIはアルファテスターからのフィードバックを基に、いくつかの具体的な成功事例を紹介しています。

GPT-4.1とほかの主要AIモデルとのベンチマーク性能比較
ソフトウェア開発分野
Windsurf社
コーディング支援プラットフォームを運営するWindsurf社では、GPT-4.1導入後:
- 内部コーディングベンチマークでGPT-4oより60%高いスコア達成
- ツール呼び出しの効率が30%向上
- 不要な編集の繰り返しが50%減少
「不要なコード閲覧や見当違いの編集提案といった異常な挙動が大幅に減少し、開発効率が向上した」という評価が得られています。
Qodo社
GitHub PRのコードレビューに特化したQodo社の200のプルリクエストでの比較テストでは:
- 55%のケースでGPT-4.1が最良の提案を行った
- 特に「提案すべきでないときに提案しない精度」と「提案すべきときの分析の包括性」で優れていた
法務・財務分野
Thomson Reuters社
法務AI「CoCounsel」にGPT-4.1を採用した結果:
- 複数文書レビューの精度が17%向上
- 文書間のコンテキスト維持能力が向上
- 複雑な法的分析において、異なる文書間の矛盾点や補足的文脈を正確に特定する能力が強化
Carlyle社
投資会社のCarlyle社の財務データ分析では:
- 複数の長文書からの詳細な財務データ抽出精度が50%向上
- 大規模文書内の密なデータからの情報取り出しが50%向上
- 「needle-in-the-haystack」取り出し、「lost-in-the-middle」エラー、文書間のマルチホップ推論などの課題を解決
その他の分野
Hex社(データサイエンスプラットフォーム):
- 最も挑戦的なSQL評価セットでほぼ2倍の性能向上
- 大規模で曖昧なスキーマからの正確なテーブル選択において大幅な改善
Blue J社(税務専門AIプラットフォーム):
- 最も挑戦的な実世界の税務シナリオに対する正確さが53%向上
- 複雑な規制の理解と長いコンテキストにわたる細かい指示の遵守能力が向上
GPT-4.1の活用法
最適なモデル選択
以下の表は、GPT-4.1ファミリーの各モデルの特性と最適な用途をまとめたものです:
| モデル | 主な特徴 | 最適なタスク | 価格(100万トークンあたり) |
|---|---|---|---|
| GPT-4.1 | 最高性能、100万トークン対応、強力なコーディング能力 | 高度なコーディング、専門分野の複雑な質問、長文書分析 | 入力:$2.00、出力:$8.00 |
| GPT-4.1 mini | GPT-4oよりも性能が高く、レイテンシを約半分に削減 | ビジネス文書作成、中程度の複雑さのコーディング、コンテンツ編集 | 入力:$0.40、出力:$1.60 |
| GPT-4.1 nano | 最も高速・低コスト、100万トークン対応 | テキスト分類、簡単な情報抽出、高頻度API呼び出し | 入力:$0.10、出力:$0.40 |
GPT-4.1ファミリーのレイテンシと知能レベルの関係
長文理解能力の活用法
分割せずに処理する利点
- 一貫性の維持:文脈の連続性が保たれ、より一貫性のある分析や要約が可能
- 相互参照の把握:文書内の離れた部分での関連情報や矛盾点を自動的に検出
- 全体像の把握:重要ポイントの抽出や優先順位付けが向上

GPT-4.1シリーズの長文コンテキスト内での情報検索精度
GPT-4.1の長文理解能力は、以下のようなXの投稿でも話題になっています:
【速報】GPT-4.1の100万トークン対応は革命的。実際にReactのコードベース8冊分を一度に処理可能になった。法律文書や研究論文、長大なコードベースを一気に分析できるこの能力は、特に法務、研究、開発分野で圧倒的な効率化をもたらす。長文処理の限界を超えた。 #GPT41 #AI革命
複数文書の同時処理
- 横断的分析:関連する複数の文書を一度に入力し、比較・統合分析が可能
- 包括的な質疑応答:「AとBの文書で矛盾している点はどこか」といった複雑な質問に対応
- 情報統合:散在する情報を一つの体系的なレポートにまとめる効率化
プロンプトキャッシュの最適活用
- コスト削減:繰り返し使用する長文コンテキストでコストを最大75%削減
- 参照文書の効率的管理:社内マニュアルや規定集をキャッシュし、低コストで質問応答を実現
実装上の注意点
- コンテキスト長が増えるほど精度は低下する傾向があるため、情報の優先順位付けを検討
- 非常に長いコンテキストでは初回応答時間が1分程度かかることを考慮したUX設計
- 重要な情報はコンテキストの冒頭または末尾に配置するのが効果的
コーディングパフォーマンスの最大化
GPT-4.1のコーディング能力は、実世界のソフトウェアエンジニアリングタスクを測定するSWE-bench Verifiedで54.6%という高いスコアを記録しています。これはGPT-4oの33.2%と比較して大幅な向上です。
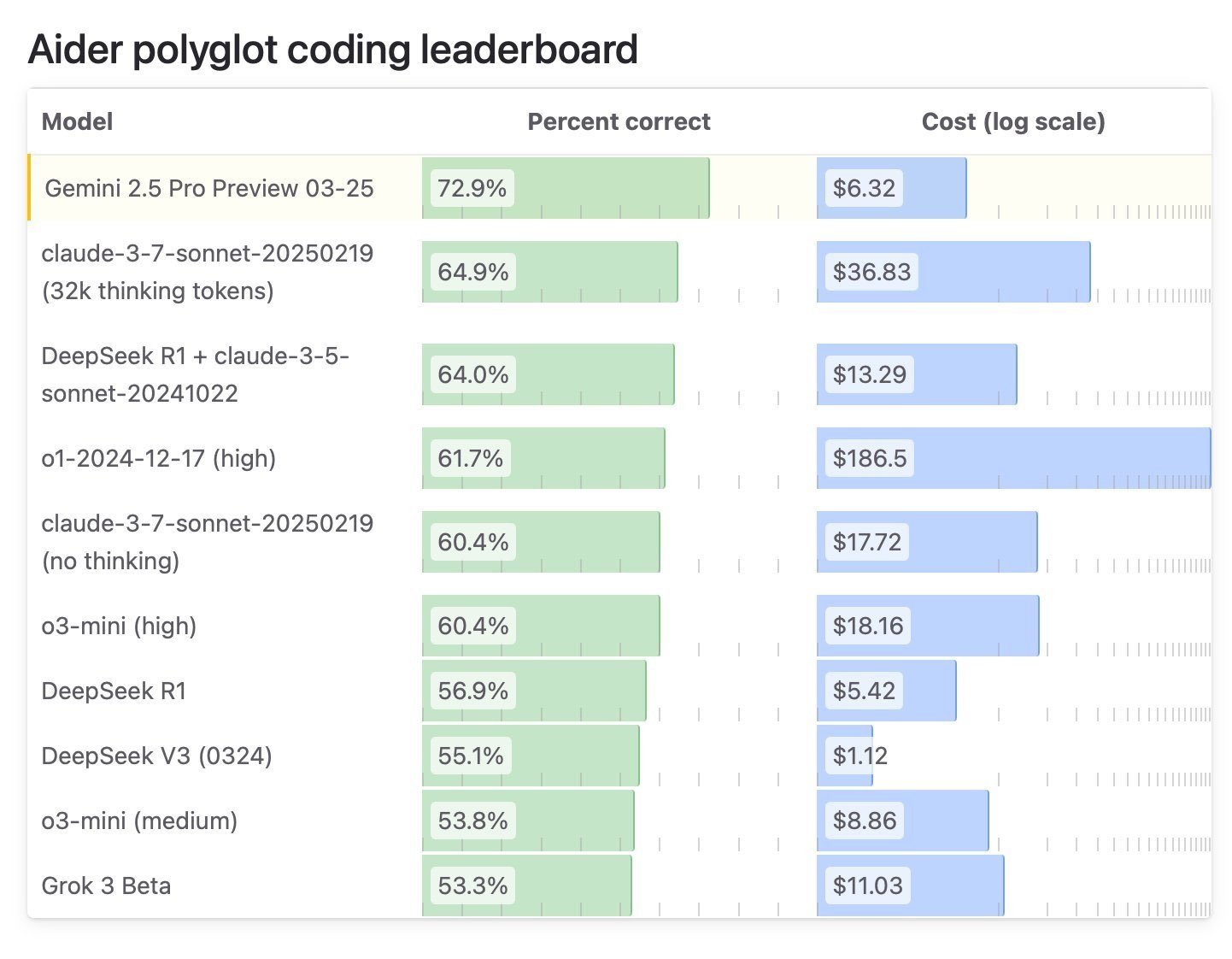
GPT-4.1と他のAIモデルのコーディングベンチマーク比較
明確な指示設計
- 具体的な要件:「単純なTodoアプリを作成して」ではなく「React Hooksを使用したローカルストレージ対応のTodoアプリを作成して」など
- コンテキストの提供:既存のコードベースやアーキテクチャについての情報を含める
- 出力形式と制約条件の明確化:完全コード、差分形式、パフォーマンス要件など
差分形式の活用
- コスト効率:大きなファイルを編集する場合、変更部分のみをdiff形式で出力
- 対応言語:ほぼすべての主要プログラミング言語のdiff形式に対応
出力トークン上限の拡大活用
- 32,768トークンの上限(GPT-4oの16,384から倍増)を活用した大規模コードベース生成
- 「Predicted Outputs」機能による大きな出力のレイテンシ削減
コードレビューとデバッグの効率化
- パフォーマンスと安全性の問題点指摘
- エラーメッセージに基づくバグ修正提案
- コードのリファクタリングとテスト生成
マルチモーダル機能の活用
画像理解の高度化
- 技術文書の図表やグラフの解析
- 複雑な図表や数式を含む視覚情報の詳細な理解
- 特定部分への注目指示による細部分析
長尺動画理解の新機能
- Video-MMEベンチマークで72.0%の高スコア達成
- 講義やプレゼンテーション動画の要約や質問応答
- 動画内の時系列パターン認識と因果関係理解
業界別活用ガイド
法務・法律業界
- 契約書分析:数百ページの契約書を一度に分析しリスク条項や矛盾点を特定
- 判例研究:大量の判例を読み込み、特定の法的論点に関する比較分析
- 法的文書生成:過去の類似案件や関連法令を参照した高品質な文書草案作成
金融・投資分野
- 財務報告書の横断的分析と財務状況変化の追跡
- 複数情報源からのリスク要因抽出・統合による包括的リスク評価
- 業界報告書、企業資料、ニュース記事の統合分析による投資判断サポート
ソフトウェア開発・IT
- 大規模コードベース分析:リポジトリ全体を理解した上での提案
- 自動コードレビュー:セキュリティ脆弱性、パフォーマンス問題の自動チェック
- レガシーコード現代化:古いコードの理解と現代的技術へのリファクタリング
医療・ヘルスケア
- 医学文献レビュー:数百の論文を同時分析した研究動向把握
- 患者記録分析:長期にわたる医療記録の一括分析による健康状態変化の評価
- 医療教育:視覚資料と併せた複雑な医学概念の説明
教育・研究
- パーソナライズド学習:学習履歴全体を分析した個別最適化教材の提案
- 研究アシスタント:数十〜数百の論文の一括分析による文献レビュー支援
- インタラクティブ教材作成:テキスト、図表、動画を統合した学習コンテンツ
GPT-4.1の限界と今後の展望
現在の限界
API限定の提供
- 現時点ではAPIのみでの提供(ChatGPTには未実装)
- ChatGPTの標準モデル(GPT-4o)には段階的に改良が取り込まれる予定
OpenAIの公式発表によると、GPT-4.1はAPI限定モデルとなり、ChatGPTには実装されません。ChatGPTユーザーは引き続きGPT-4oを使用することになりますが、GPT-4.1の改良点は段階的にGPT-4oに取り込まれる予定です。#GPT41 #OpenAI
長文処理の現実的制約
- コンテキスト長が増加するほど精度は低下(100万トークンでは約50%に低下)
- 100万トークンのコンテキストでは初回トークン生成に約1分必要
競合モデルとの関係
- GoogleのGemini 2.5 ProやAnthropicのClaude 3.7など一部ベンチマークで優位性のあるモデルも存在
- 日本語文章力はGPT-4.1の強みだが、他領域では競合にも強みがある
指示の明確さへの依存
- より指示に忠実な傾向があり、曖昧な指示では期待通りの結果が得られないことがある
- 具体的で明確な指示を与えることがパフォーマンス最大化に不可欠
今後の展望
エージェント開発の加速
- 高度な指示理解と長文処理能力による自律型AIエージェント開発の加速
- Responses APIなどと組み合わせたより自律的なタスク実行の実現
マルチモーダル対話の深化
- テキスト、画像、音声、動画を統合的に処理する自然インターフェースの発展
- リアルタイム視覚情報を取り込みながら会話できるAIアシスタントの可能性
AI技術の民主化とコスト効率化
- GPT-4.1ファミリーの価格設定による高性能AI利用ハードルの低下
- 中小企業や個人開発者にも手の届く価格帯による普及拡大
次世代モデルへの布石
- GPT-4.5 Previewの2025年7月14日終了と次世代モデル開発への移行
- より効率的なモデルへの注力による計算コスト最適化の進展
まとめ:GPT-4.1がもたらす変革
GPT-4.1の登場は、AIモデルの進化における重要なマイルストーンです。主な技術的進化は:
- 100万トークンコンテキスト処理能力
- コーディング能力の劇的向上(SWE-benchで54.6%の高スコア)
- マルチモーダル理解の強化
- 高性能と低コストの両立(従来より26%のコスト削減)
- 指示遵守能力の向上
実用面でのインパクト
- 開発生産性の飛躍的向上
- 知識労働の効率化(法務、金融、研究分野での文書処理・分析効率化)
- AIアクセシビリティの向上
- エージェントAIの能力強化
日本語ユーザーにとっての意義
日本語の表現力の高さは大きなメリットです。文章作成、編集、翻訳タスクにおいて、より自然で読みやすい文章を生成できる能力は多くのビジネスシーンで価値を発揮します。ユーザーテストでは特に「不自然さ」や「機械翻訳感」の減少が高く評価されています。
「より少ないコストで、より大きな仕事を任せられるAI」として、GPT-4.1は目的と予算に応じた適切なモデル選択の幅を広げ、AIの真の実用化時代の到来を象徴しています
この記事の著者 / 編集者

